AITV: A Unified Cross-Modal Generation System for Audio, Image, Text, and Video
A production-grade multimodal system that enables seamless conversion between audio, image, text, and video using a unified latent representation.

Project Overview
Traditional AI systems treat audio, image, text, and video as isolated domains. This fragmentation introduces friction when building real-world products that require seamless transformation between modalities. AITV addresses this limitation by introducing a unified cross-modal architecture that allows any modality—audio, image, text, or video—to be converted into any other modality through a shared semantic representation.
System Architecture
AITV is built around a hub-and-spoke multimodal architecture. All incoming modalities are first encoded into a shared semantic latent space. From this unified representation, specialized decoders generate the target modality. This avoids lossy chained conversions and enables true cross-compatibility.
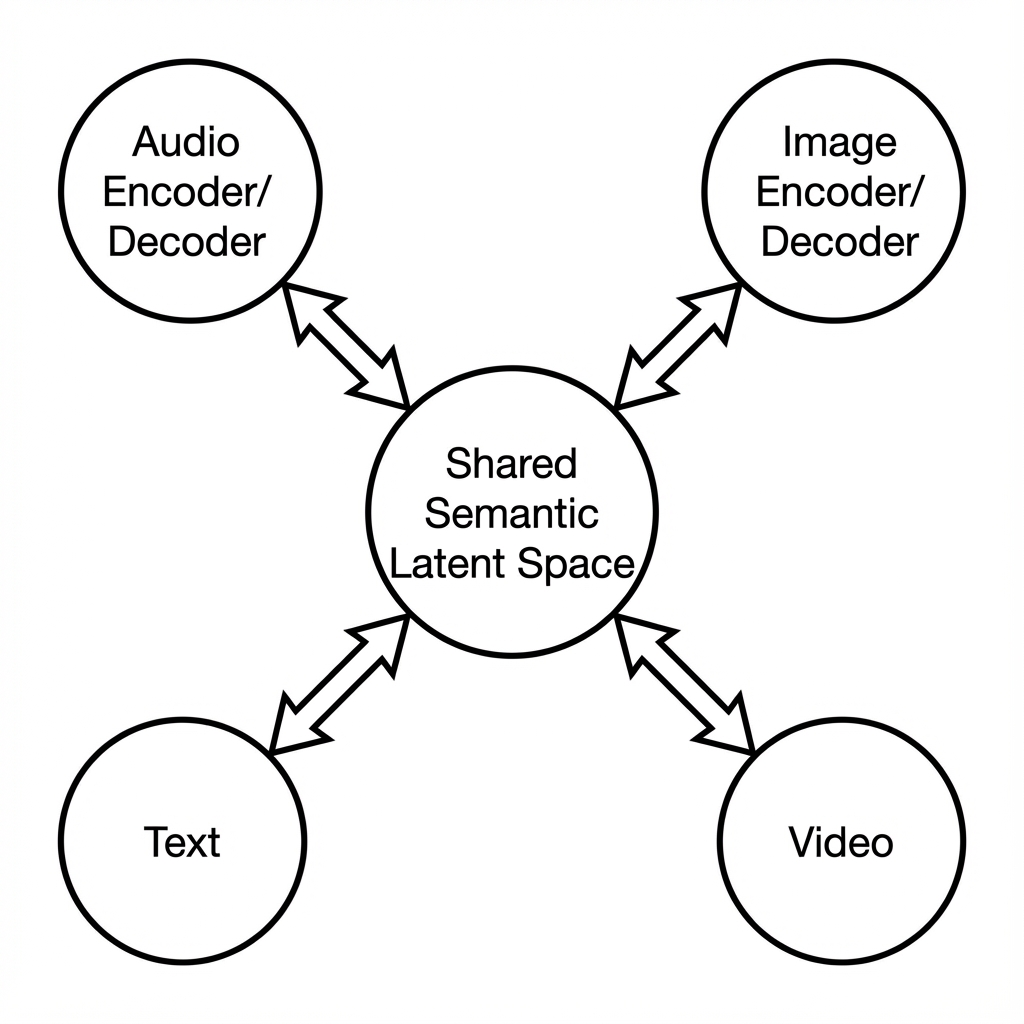
Modality Encoders
Dedicated encoders for audio, image, text, and video that transform raw inputs into a normalized semantic latent representation.
Shared Semantic Latent Space
A modality-agnostic representation capturing intent, structure, and meaning independent of source format.
Modality Decoders
Specialized generators that transform the shared latent representation into the target modality.
Cross-Modal Orchestrator
Controls routing, validation, and transformation logic between encoders and decoders.
Validation & Consistency Layer
Ensures semantic integrity and detects information loss during conversion.
Implementation Details
Code Example
# Cross-Modal Orchestrator Example
from aitv import ModalityEncoder, SemanticLatentSpace, ModalityDecoder
class CrossModalOrchestrator:
def __init__(self):
self.encoders = {
'audio': AudioEncoder(),
'image': ImageEncoder(),
'text': TextEncoder(),
'video': VideoEncoder()
}
self.latent_space = SemanticLatentSpace()
self.decoders = {
'audio': AudioDecoder(),
'image': ImageDecoder(),
'text': TextDecoder(),
'video': VideoDecoder()
}
async def convert(self, input_data, source_modality: str, target_modality: str):
# Encode source modality to shared latent space
latent = await self.encoders[source_modality].encode(input_data)
# Validate semantic integrity
validated_latent = self.latent_space.validate(latent)
# Decode to target modality
output = await self.decoders[target_modality].decode(validated_latent)
return outputAgent Memory
By enforcing a single semantic latent space, AITV eliminates the compounding errors typically introduced by chained modality conversions.
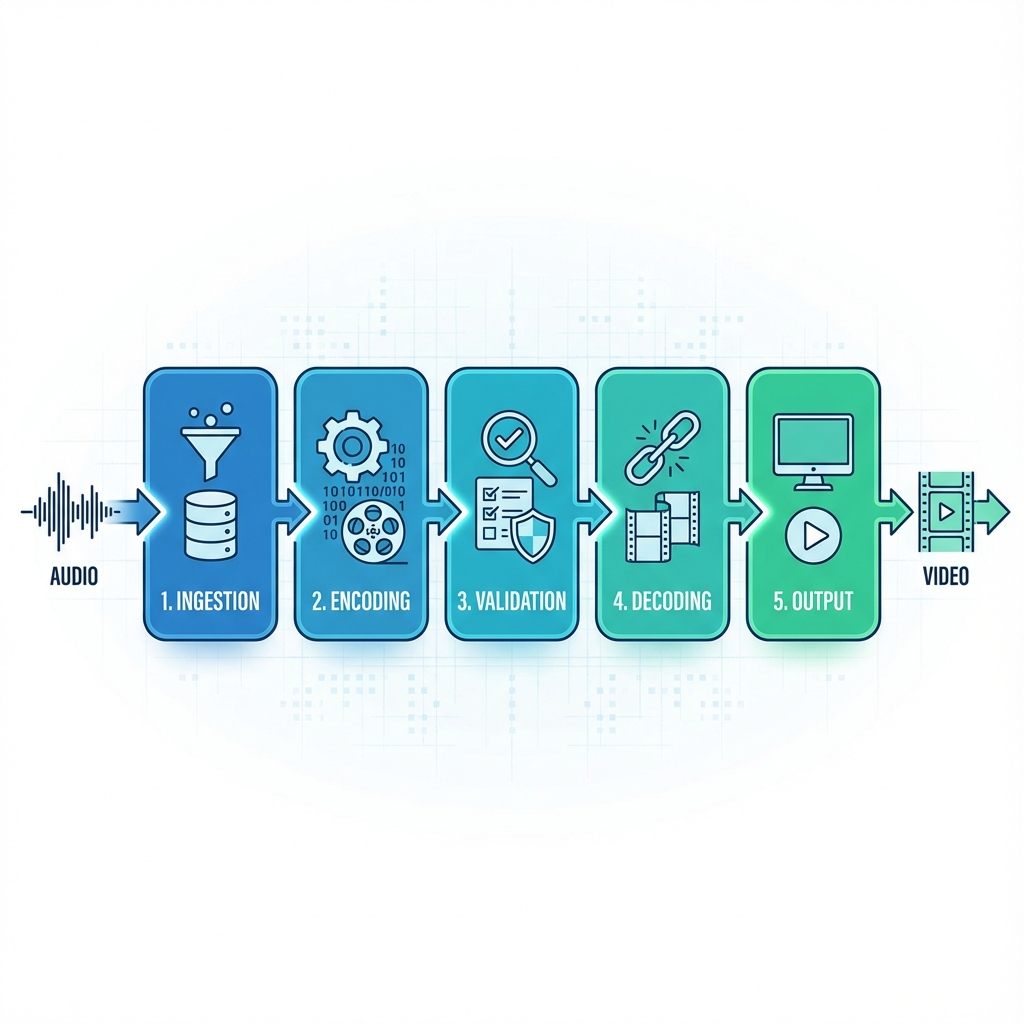
Workflow
Ingestion: Raw modality input (audio, image, text, or video) enters the pipeline.
Encoding: The appropriate modality encoder transforms input into the shared semantic latent space.
Validation: The consistency layer verifies semantic integrity and detects potential information loss.
Decoding: The target modality decoder generates the output from the latent representation.
Output: Final converted content is returned with confidence metrics.
Results & Impact
"AITV fundamentally changed how we approach multimodal content pipelines. Converting between audio, video, and text is now seamless and reliable."
Cross-Compatibility
Any modality can be converted to any other without restructuring the pipeline.
Semantic Consistency
Meaning and intent are preserved across transformations.
Scalability
New modalities can be added without rearchitecting the system.
About the Author
Vedant Pai
AI Context Engineer
Apex Neural
Designs and deploys agentic AI that integrates LLM reasoning with structured backends. Work spans multi-agent orchestration (Planner/Executor/Verifier), ReAct pipelines, RAG with validation, and microservice deployments with JWT/RBAC.
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.