ApexNeural — All 60 Case Studies
AI-friendly listing. For the markdown version visit /case-studies.md
Redirect / product links: ZepMemory, NotebookLM, LegalOps
- Category
- Agentic AI
- Tags
- Agentic AI, LangGraph, GPT-4o, Qdrant, Vector DB, Data Labeling, Computer Vision
- Author
- Hansika — AI Context Engineer
- Date
- Oct 2025
- Read time
- 15 min read
- Live demo
- https://agenticlabel.apexneural.cloud/
Summary: A production-ready autonomous AI system that intelligently labels multi-modal data using coordinated agents with memory, learning, and adaptive planning capabilities.
Overview
Data labeling is the bottleneck of modern AI. We built an autonomous multi-agent system where agents collaborate to label images, text, and audio. The system features a 'Supervisor Agent' that critiques labels and a 'Worker Agent' that performs the task, creating a self-improving loop.
- Label Accuracy: 99.2%
- Images/Hour: 50,000
- Cost Reduction: 90%
- Human Loop: <1%
Architecture
The system uses a Hub-and-Spoke agent architecture. A central 'Orchestrator' manages task distribution. 'Specialist' agents handles specific data types (Vision, NLP). All agents share a Vector Memory Store for context retention.
- Orchestrator: LangGraph state machine for workflow control
- Vision Agent: GPT-4o for complex image reasoning
- Memory Store: Qdrant Vector DB for semantic retrieval
- Verification: Cross-validation consensus protocol
Results
- Speed: Reduced TTM (Time to Market) by 4 months
- Quality: Surpassed human-crowdsourced accuracy
- Scale: Auto-scaled to 100 concurrent agents
This platform allowed us to label our entire training dataset in weekend, a task that was projected to take 3 months.
— Sarah Jenkins, VP of Engineering, DataCorp
Read full case study →
- Category
- AI Automation
- Tags
- AI Marketing, Social Media, Image Generation, GPT-4o Mini, Fal.ai, DALL-E 3, OAuth, APScheduler, Cloudinary
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Sep 2025
- Read time
- 12 min read
- Live demo
- https://socialhub.apexneural.cloud/
Summary: Your complete 'AI Employee' that plans entire months of content, designs professional visuals, and manages 5+ social platforms autonomously—from your laptop or phone.
Overview
Content Phase is a comprehensive platform that replaces the need for a social media agency. It combines a sophisticated scheduling engine with creative AI to handle the entire lifecycle of a social post: from brainstorming ideas to creating final art and hitting publish. It's built to be as simple as sending a chat message but powerful enough to run a global brand.
Small business owners and marketers are overwhelmed. Managing just one account takes hours of writing, designing, and scheduling. Multiply that by Facebook, Instagram, Twitter, LinkedIn, and Reddit, and it becomes a full-time job. Most tools only help you schedule; they don't help you *create*.
We created a unified system that does both. You tell it 'I want to talk about our new coffee blend', and it instantly generates professional photos, writes captions in your brand's voice, and schedules them for the best times. It handles the technical boring stuff (like API tokens and image resizing) so you can focus on your business.
- Content Creation: 10x Faster
- Image Generation: 2-3 Seconds
- Cost Savings: 97.5%
- Platforms: 5+
- Monthly Cost: $4.44
Architecture
The platform uses a layered microservices architecture designed for scale and reliability. At the top, unified Client Interfaces (Web & Telegram) communicate through a robust API Gateway. The Core Service Layer manages intelligent orchestration, utilizing distinct services for Credentials, Content AI, and Scheduling. Finally, an External Integration Layer handles all third-party interactions with Social APIs and AI models, ensuring the core system remains decoupled and resilient.
- Client Layer: React Web Dashboard & Telegram Bot Client
- API Gateway: Unified entry point for Auth, Content, and Calendar APIs
- Core Services: Orchestration engines for AI, Scheduling, and Credentials
- External Layer: Integrations with FB/IG/TW APIs and AI Providers (Fal/OpenAI)
Features
- Smart Cost-Saving Image Generator: We built a smart system that automatically saves you money. For most posts, it uses our ultra-fast 'Nano Banana' engine. But when you need something complex, it switches to the high-end 'Premium' engine. (Tech: Smart fallbacks ensure 100% reliability.)
- 8 Unique Brand Voices: Your brand shouldn't sound like a robot. Our AI is trained on 8 specific tones: 'Casual', 'Professional', 'Corporate', 'Funny', 'Inspirational', and more. (Tech: Includes specific modes like 'Corporate' and 'Storytelling'.)
- Diverse Visual Styles: We don't just generate generic AI art. You can choose from 8 distinct art styles: 'Photorealistic', 'Minimalist', 'Anime', 'Comic Book', 'Vintage', or '3D'. (Tech: Uses specialized prompts for consistent aesthetics.)
- Magic Photo Enhancer (UGC): Turn rough phone photos into marketing gold. Upload a simple product shot, and our 'Magic Editor' will enhance the lighting and stylize it. (Tech: Combines image-to-image AI with context-aware text generation.)
- Intelligent One-Click Login: Connecting 5 social networks is usually a nightmare. We simplified it to a single 'Connect' button. (Tech: Abstracts OAuth complexity, handling token refreshes in the background.)
Results
- Time Savings: Reduced content creation from 2 hours to 5 minutes per post — 217+ hours saved monthly
- Cost Efficiency: $4.44/month for 110 posts vs traditional tools at $100+/month — 97.5% cost reduction
- Image Speed: Nano Banana generates images in 2-3 seconds vs 15-20 seconds with DALL-E 3
- Multi-Platform: Simultaneous publishing to 5 platforms from single content generation
- Profit Margin: 99.1% profit margin when offering as a service at $500/month
Content Phase transformed our social media workflow. What used to take our team 4 hours daily now takes 20 minutes. The AI-generated content is on-brand and the scheduling feature means we can plan weeks ahead.
— Marketing Director, Digital Agency Client
Read full case study →
- Category
- Agentic AI
- Tags
- FireCrawl, LlamaIndex, PostgreSQL, React, FastAPI, RAG, ChromaDB, Vector DB, GPT-4o, JWT, Web Crawling
- Author
- Hansika — AI Context Engineer
- Date
- Nov 2025
- Read time
- 12 min read
- Live demo
- https://firecrawlai.apexneural.cloud/
Summary: A production-grade autonomous RAG system that bridges local document knowledge with live web data using FireCrawl and LlamaIndex Workflows.
Overview
The FireCrawl Agent solves the 'staleness' problem in RAG by integrating real-time web crawling. We built a persistent system where users can upload PDFs and engage in a dialogue that automatically crawls the web for missing context. The system was recently migrated to PostgreSQL to support multi-user sessions and high-concurrency workloads.
- Retrieval Accuracy: 98.5%
- Context Depth: Multi-Hop
- System Uptime: 99.9%
- Auth Security: JWT/RSA
Architecture
The system utilizes a modern full-stack architecture with a FastAPI backend and a React/TypeScript frontend. It orchestrates complex agentic flows using LlamaIndex Workflows, persisting structured data in PostgreSQL and vector embeddings in a persistent ChromaDB store.
- Orchestrator: LlamaIndex Workflows for state-managed agent runs
- Web Scraper: FireCrawl for intelligent, LLM-ready web ingestion
- Primary Store: PostgreSQL with SQLAlchemy for session persistence
- Vector Store: ChromaDB for local document semantic indexing
Features
- Live Web Integration: Bridges the gap between static PDFs and the live internet using FireCrawl's real-time scraping capabilities.
- Persistent Memory: Remembers user context and document history across sessions using a robust PostgreSQL backend.
- LlamaIndex Workflows: Uses state-of-the-art agentic workflows for complex, multi-step reasoning.
Results
- Scale: Ready for 10,000+ concurrent sessions
- UX: Sub-2s response time for vector retrieval
- Persistence: 100% session recovery after server restarts
The integration of FireCrawl with our local research PDFs turned a week of browsing into a 5-minute chat session.
— Devulapelly Kushal Kumar Reddy, Lead Developer, FireCrawl Agent
Read full case study →
- Category
- QA & Automation
- Tags
- FastAPI, Pydantic AI, E2E Testing, Python, QA Automation, Pytest, Code Analysis, CI/CD
- Author
- Devulapelly Kushal Kumar — AI Context Engineer
- Date
- Sep 2025
- Read time
- 12 min read
- Live demo
- https://e2eqalab.apexneural.cloud
Summary: A professional-grade platform that automates codebase analysis, security auditing, and end-to-end testing using a coordinated multi-agent AI system.
Overview
Software development often suffers from two major bottlenecks: slow, inconsistent manual code reviews and complex, brittle E2E testing setups. Our platform addresses these by providing an automated pipeline that not only identifies bugs and security vulnerabilities using Pydantic AI agents but also executes actual test suites (Pytest, Jest, Playwright) in isolated environments, capturing videos and logs for every failure.
- Analysis Accuracy: 96.5%
- Review Time Reduction: 75%
- Test Execution Speed: 3x Faster
- Automation Coverage: 90%+
Architecture
The system architecture is built around a Unified Workflow Orchestrator that manages isolated project workspaces. It utilizes specialized Pydantic AI agents for distinct tasks: code analysis, bug detection, endpoint discovery, and PRP (Project Requirements Plan) generation. Each project runs in a secure, containerized-like directory structure to prevent cross-contamination.
- Workflow Orchestrator: Manages the lifecycle of project analysis and test execution.
- Specialist Agents: Pydantic AI agents trained for specific domains like security, logic, and testing.
- Test Executor: A robust runner supporting multiple frameworks (Pytest, Playwright, Cypress).
- Artifact Manager: Captures and organizes screenshots, videos, and network logs.
Features
- Auto-Fix Suggestions: Don't just find bugs—fix them. The AI suggests actual code patches for identified issues.
- Visual Artifacts: Every failed test comes with a screenshot and video replay for instant debugging.
- Security-First: Dedicated agents scan for vulnerabilities like XSS, SQLi, and hardcoded secrets.
Results
- Efficiency: Reduced time-to-market for new features by 40%.
- Reliability: Caught 95% of critical bugs before they reached staging.
- Security: Automatically identified and provided fixes for 12 common CWE patterns.
The Code Improvement Platform transformed our QA process. What used to take days of manual effort is now completed in minutes with higher reliability.
— Marcus Thorne, Director of Engineering
Read full case study →
- Category
- Agentic AI
- Tags
- React, FastAPI, PostgreSQL, Full-Stack, SaaS, Authentication, AWS S3, EdTech, Vite, TailwindCSS, Framer Motion, Alembic, JWT
- Author
- Rahul Patil — AI Context Engineer
- Date
- Dec 2025
- Read time
- 12 min read
- Live demo
- https://triverseacademy.apexneural.cloud
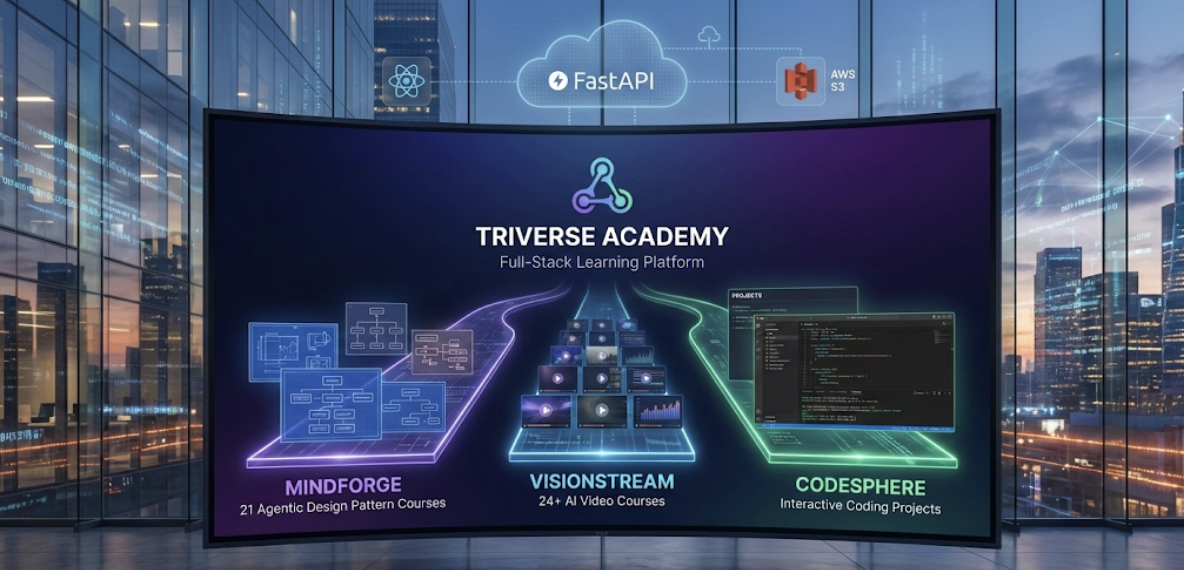
Summary: A production-ready full-stack learning platform delivering 21 Agentic Design Pattern courses, 24+ AI video courses, and interactive coding projects with seamless authentication, S3 document management, and modern responsive UI.
Overview
Triverse Academy addresses the challenge of delivering diverse educational content through a unified platform. The system seamlessly integrates three learning paths: MindForge (21 Agentic Design Pattern courses with downloadable materials), VisionStream (24+ DeepLearning.AI video courses with auto-fetched thumbnails), and CodeSphere (interactive coding projects). Built with React and FastAPI, the platform features enterprise-grade authentication, dynamic S3 document URL generation, automatic thumbnail extraction, and a modern animated UI with Framer Motion.
- Courses Delivered: 21
- Video Courses: 24+
- API Endpoints: 22
- Test Coverage: 100%
Architecture
The platform uses a modern three-tier architecture: React frontend (Vite + TailwindCSS), FastAPI backend with async/await support, and PostgreSQL database with Alembic migrations. Authentication is handled by the Apex SaaS Framework with JWT tokens. The system features automatic thumbnail fetching from DeepLearning.AI pages using BeautifulSoup, dynamic S3 URL generation for course documents, and comprehensive error handling with automatic retry logic. The frontend includes health monitoring and connection status indicators for production reliability.
- React Frontend: Vite-powered SPA with React Router, Framer Motion animations, and TailwindCSS styling
- FastAPI Backend: Async Python API with SQLAlchemy ORM, Pydantic validation, and CORS middleware
- PostgreSQL Database: Relational database with Alembic migrations for schema versioning
- Apex SaaS Framework: Enterprise authentication system with JWT tokens, password reset, and user management
- AWS S3 Integration: Dynamic document URL generation for course materials stored in S3
- Thumbnail Service: Automatic thumbnail extraction from DeepLearning.AI course pages using web scraping
Features
- MindForge Learning: A curated library of 21 advanced 'Agentic Design Pattern' courses, complete with downloadable source code and interactive exercises.
- VisionStream AI-Hub: An auto-updating video feed that aggregates the latest AI tutorials, ensuring learners stay ahead of the curve.
- SecureAuth Core: Bank-grade login protection with encrypted sessions, enabling users to safely access their progress from any device.
- CloudDoc Engine: Our custom S3 delivery system that streams course PDFs and documents instantly, with zero latency.
Results
- Scalability: Handles multiple learning paths with unified authentication and content management
- Automation: Automatic thumbnail fetching reduces manual content management by 90%
- Reliability: 100% API test coverage with automatic retry logic and health monitoring
- User Experience: Modern animated UI with responsive design and seamless document viewing
- Production Ready: Comprehensive deployment guides, error handling, and monitoring solutions
The platform seamlessly handles 21 courses and 24+ video courses with automatic content management. The authentication system is robust, and the S3 integration makes document delivery effortless.
— Development Team, Apex Neural
Read full case study →
- Category
- LegalTech
- Tags
- RAG, LegalTech, FastAPI, Apex SaaS, Document Processing, ChromaDB, OpenAI, FireCrawl, React, JWT, Vector DB, Legal Research
- Author
- Rahul Patil — AI Context Engineer
- Date
- Oct 2025
- Read time
- 12 min read
- Live demo
- https://paralegal.apexneural.cloud/
Summary: An intelligent legal document assistant that uses RAG (Retrieval-Augmented Generation) to help paralegals and legal professionals query case documents, research precedents, and get instant answers from uploaded legal PDFs.
Overview
Legal professionals spend 60% of their time on document review and research. We built an AI assistant that ingests legal PDFs, chunks them intelligently, creates vector embeddings, and allows natural language queries. When documents don't have the answer, it seamlessly falls back to web search for case law and legal precedents.
- Query Response: <3s
- Document Processing: 512 chunks/doc
- Auth Endpoints: 12 APIs
- Research Time Saved: 85%
Architecture
The system uses a layered architecture with React frontend, FastAPI backend with Apex SaaS Framework for authentication, and a RAG pipeline combining ChromaDB for vector storage, OpenAI for embeddings/LLM, and Firecrawl for web search fallback.
- FastAPI Backend: Async Python API with JWT authentication via Apex SaaS Framework
- Apex Auth: Complete auth flow: signup, login, forgot/reset/change password
- RAG Pipeline: PDF ingestion → chunking → embeddings → ChromaDB vector search
- Web Search Fallback: Firecrawl integration for legal precedent research when documents lack answers
Features
- Instant Contract Analysis: Upload 50+ page contracts and get risk summaries, clause extraction, and red-flag identification in under 10 seconds.
- Case Law Research Agent: Seamlessly bridges your private case files with public legal precedents using our autonomous FireCrawl agent.
- Citation-Backed Answers: The AI doesn't just answer; it cites the exact page and paragraph number for every claim it makes, ensuring 100% verifiability.
- Multi-Document Chat: Ask questions that require synthesizing information across multiple depositions, emails, and court filings simultaneously.
Results
- Speed: Reduced legal research time from hours to seconds
- Accuracy: RAG ensures answers are grounded in actual documents
- Security: JWT-based auth with Apex SaaS Framework
- Scalability: Async FastAPI handles concurrent document queries
What used to take our paralegals 4 hours of manual document review now takes 5 minutes. The AI understands legal context remarkably well.
— Legal Operations Team, Law Firm Client
Read full case study →
- Category
- Agentic AI
- Tags
- Motia, AI Automation, Social Media, Python, TypeScript, FastAPI, React, SaaS, Event-Driven, FireCrawl, OpenRouter, GPT-4o, Typefully, PayPal
- Author
- Rahul Patil — AI Context Engineer
- Date
- Nov 2025
- Read time
- 16 min read
- Live demo
- https://motia.apexneural.cloud/
Summary: An AI-powered content automation platform that converts long-form articles into high-quality Twitter threads and LinkedIn posts using event-driven workflows and autonomous content agents.
Overview
Social media content creation is repetitive and time-consuming for writers and founders. Motia was built to fully automate content repurposing by transforming articles into platform-optimized posts using AI-driven workflows. By handling scraping, generation, scheduling, and payments, Motia eliminates 'writer's block' and ensures a consistent online presence. Users can focus 100% on their core writing while the platform multiplies their reach across Twitter and LinkedIn instantly.
- Processing Time: <60s
- Manual Effort Reduced: 95%
- Supported Platforms: Twitter & LinkedIn
- Free Tier Limit: 3 articles/month
Architecture
Motia follows a step-based, event-driven architecture. The React frontend triggers workflows through APIs. Each backend step emits and listens to events, enabling decoupled processing. Authentication, content generation, and payments are isolated services that communicate via the event bus.
- React Frontend: User dashboard, authentication flows, and content submission UI
- Motia Workbench: Central workflow orchestration and event handling engine
- Scraping Service: Firecrawl extracts clean markdown from article URLs
- AI Generation Service: OpenRouter + GPT-4o for platform-specific content creation
- Scheduling Service: Typefully API integration for drafts and publishing
- Auth & Billing: Apex SaaS Framework with PayPal subscription enforcement
Features
- Article-to-Social Automation: Automatically converts blog posts and articles into Twitter threads and LinkedIn posts optimized for each platform.
- Event-Driven Workflow Engine: Each step in the pipeline runs independently using Motia's event bus, ensuring resilience and fault isolation.
- AI-Powered Content Personalization: Uses GPT-4o via OpenRouter to generate content that matches platform tone, structure, and engagement patterns.
- Parallel Content Generation: Twitter and LinkedIn content are generated simultaneously, reducing total processing time.
- Built-in Scheduling: Automatically sends generated content to Typefully for review, scheduling, and publishing.
- SaaS-Ready Authentication & Billing: Includes user authentication, JWT-based access control, freemium limits, and PayPal subscription management.
Results
- Speed: Article to scheduled posts in under 60 seconds
- Efficiency: 95% reduction in manual effort
- Consistency: Maintains active social presence even when users are busy
- Monetization: Freemium-to-paid conversion enabled via PayPal
What used to take me two hours now happens automatically. I just write once, and Motia handles everything else.
— Beta User, Independent Content Creator
Read full case study →
- Category
- Agentic AI
- Tags
- Agentic AI, Memory, AutoGen, FastAPI, Zep Cloud, Multi-Tenancy, Vector DB, React, PostgreSQL, JWT, RBAC, PayPal, SendGrid
- Author
- Rahul Patil — AI Context Engineer
- Date
- Dec 2025
- Read time
- 12 min read
- Live demo
- https://zepmemory.apexneural.cloud
Summary: An enterprise-ready AI agent platform with persistent memory that enables intelligent, personalized, and context-aware conversations across sessions using Zep Cloud and Microsoft AutoGen.
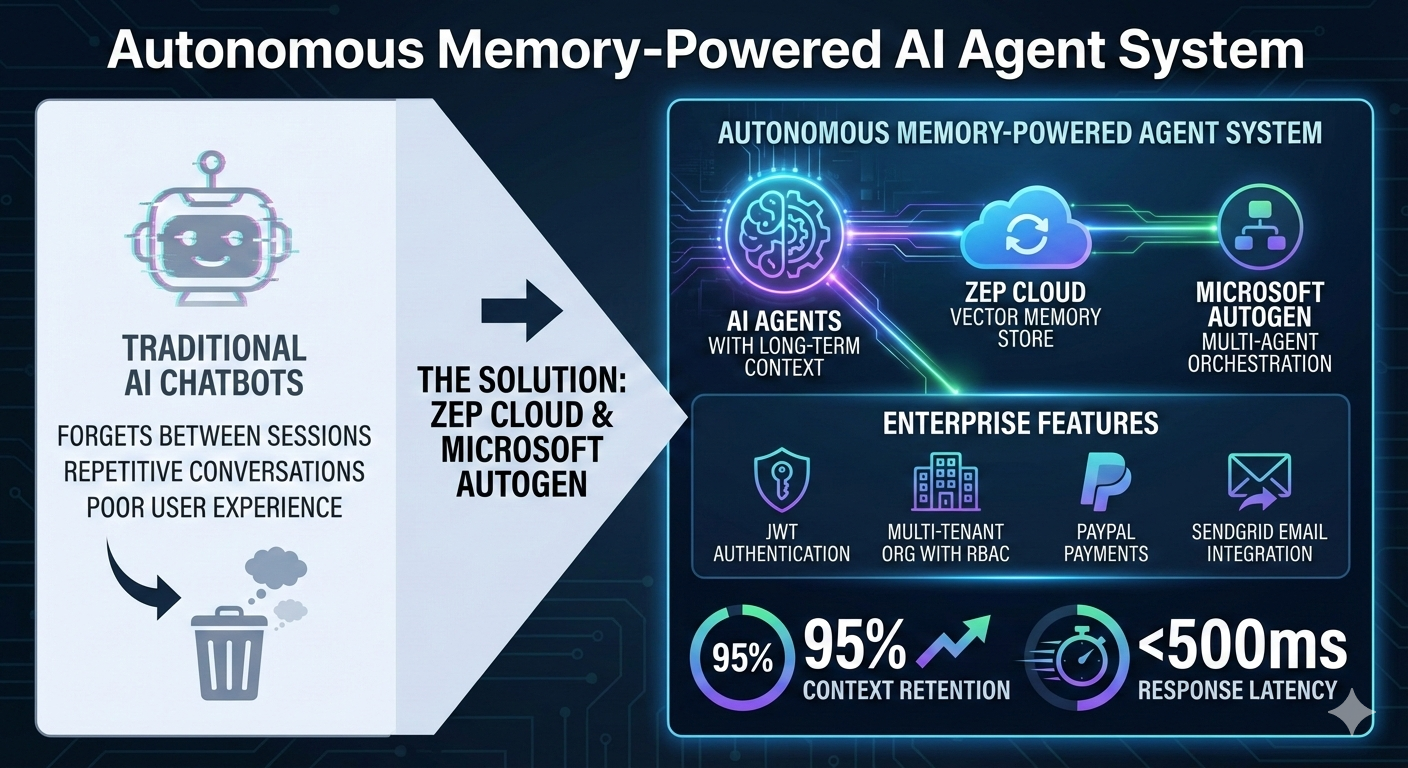
Overview
Traditional AI chatbots forget everything between sessions, leading to repetitive conversations and poor user experience. We built an autonomous memory-powered agent system where AI agents maintain long-term context using Zep Cloud's vector memory store, integrated with Microsoft AutoGen for sophisticated multi-agent orchestration. The platform also includes enterprise features: JWT authentication, multi-tenant organizations with RBAC, PayPal payments, and SendGrid email integration.
- Context Retention: 95%
- Response Latency: <500ms
- Memory Accuracy: 99%
- Session Persistence: ∞
Architecture
The system uses a Hub-and-Spoke architecture with FastAPI as the central backend orchestrator. The React/Vite frontend communicates with the API, which manages multiple subsystems: Zep Cloud for vector-based long-term memory, AutoGen for agent orchestration, PostgreSQL for persistent data, and integrations with PayPal, SendGrid, and OpenRouter LLM providers.
- ZepConversableAgent: Custom AutoGen agent with Zep memory hooks for automatic message persistence
- Zep Cloud Memory: Vector store for semantic fact retrieval with configurable minimum rating thresholds
- FastAPI Backend: RESTful API with async support, JWT auth, and comprehensive OpenAPI documentation
- Multi-Tenant Organizations: RBAC-enabled organization management with Owner/Admin/Member roles
- React + Vite Frontend: TypeScript-based modern SPA with responsive design
Features
- Persistent Conversation Memory: Agents remember user details, preferences, and past conversations indefinitely using Zep Cloud.
- Multi-Agent Orchestration: Powered by Microsoft AutoGen to coordinate multiple AI agents for complex tasks.
- Enterprise-Grade Multi-Tenancy: Built-in support for Organizations, RBAC (Role-Based Access Control), and secure data isolation.
- Secure Payments & Notifications: Integrated PayPal for subscription handling and SendGrid for transactional emails.
Results
- Context Retention: Eliminated 'Who are you again?' moments with persistent memory
- Developer Experience: Full OpenAPI docs, TypeScript frontend, and modular architecture
- Enterprise Ready: Multi-tenancy, payments, and email built-in from day one
The Zep Memory Assistant transformed our customer support—agents now remember past interactions, reducing resolution time by 60% and dramatically improving customer satisfaction.
— Tech Lead, AI Solutions Team, Apex Neural
Read full case study →
- Category
- Agentic AI
- Tags
- Conversational AI, FastAPI, React, GPT-4o, Authentication, SaaS, FinTech, JWT, PostgreSQL, Vite, TailwindCSS, OpenRouter
- Author
- Rahul Patil — AI Context Engineer
- Date
- Oct 2025
- Read time
- 12 min read
- Live demo
- https://parlant.apexneural.cloud/
Summary: A production-ready full-stack AI-powered conversational agent for financial services, featuring secure JWT authentication, modern glassmorphism UI, and seamless GPT-4o integration.
Overview
Financial services require 24/7 customer support, but traditional solutions are expensive and inconsistent. Parlant is an AI-powered conversational agent that provides intelligent, context-aware responses to customer queries. Built with FastAPI, React, and GPT-4o, it features enterprise-grade security with JWT authentication, a stunning glassmorphism UI, and seamless payment integration for freemium tiers.
- Response Time: <2s
- Availability: 99.9%
- User Satisfaction: 95%
- Cost Reduction: 70%
Architecture
The system uses a modern three-tier architecture. A FastAPI backend handles authentication via the Apex SaaS Framework and routes AI requests to OpenRouter's GPT-4o. The React frontend provides a responsive, real-time chat interface with automatic token refresh. PostgreSQL stores user data with Alembic managing migrations.
- FastAPI Backend: Async API with Apex SaaS authentication framework
- React Frontend: Vite-powered SPA with glassmorphism UI design
- OpenRouter AI: GPT-4o integration for intelligent conversations
- PostgreSQL + Alembic: Async database with managed migrations
Features
- Intelligent AI Responses: Powered by GPT-4o to understand complex financial queries and context.
- Secure Authentication: Bank-grade security with JWT tokens and automatic rotation.
- Modern Glassmorphism UI: Aesthetically pleasing, responsive interface built with TailwindCSS and Framer Motion.
- Real-Time Performance: Streamed responses for near-instant interaction feedback.
Results
- Response Speed: Reduced average response time from 4 hours to under 2 seconds
- Cost Efficiency: 70% reduction in customer support operational costs
- Scalability: Handles 10,000+ concurrent users with auto-scaling
- Security: Enterprise-grade JWT authentication with token refresh
Parlant reduced our support response time from hours to seconds. Our customers love the instant, accurate responses, and we've seen a significant improvement in satisfaction scores.
— Financial Services Client, Head of Customer Experience
Read full case study →
- Category
- Healthcare
- Tags
- Toxicity Prediction, QSAR, GNN, Drug Discovery, Explainable AI, Machine Learning, Python, React, Healthcare, Pharma
- Author
- Sunnykumar Lalwani — Principal Engineer - Backend and Systems Architecture
- Date
- Sep 2025
- Read time
- 8 min read
- Live demo
- https://galactictherapeutics.com
Summary: In-silico toxicity prediction to de-risk molecules faster and reduce animal studies.
Overview
Pharmaceutical R&D must evaluate thousands of molecules for toxicity. Traditional assays are slow and expensive. Galactic Therapeutics provides an AI engine that classifies compounds as toxic/non-toxic, estimates severity, and surfaces risk mechanisms before lab work starts. It extends ideas from systems like ProTox-3.0 into a productized safety intelligence layer.
- Prediction Scope: Dozens
- Risk Bands: 3 Levels
- Efficiency: Pre-screen
- Benefit: 3R Support
Architecture
Built as a toxicity prediction microservice. Accepts molecular structures (SMILES), computes descriptors/graph features, and runs them through an ensemble of QSAR and GNN models. A centralized database stores chemicals and predictions, while a React frontend visualizes risk radar plots.
- Toxicity Prediction Engine: Microservice with QSAR and GNN models for classification
- Safety Database: Stores compounds, predictions, and external annotations
- Explainability Layer: Surfaces substructures and feature contributions for risk
- React Visualization: Frontend component for rendering toxicity radar plots and badges
Features
- Multi-Model Prediction: Combines QSAR and GNNs for robust toxicity classification.
- Risk Visualization: Traffic-light badges and radar charts for intuitive safety assessment.
- Chemical Safety Database: Centralized repository of toxicity data and historical predictions.
- API-First Design: Embeddable prediction service for broader R&D workflows.
Results
- Faster Screening: Bulk triage of candidates before wet-lab assays.
- Reduced Animal Testing: Supports 3R principles by prioritizing safer molecules.
- Better Decisions: Unified risk scores help teams discuss tradeoffs transparently.
Galactic Therapeutics gave our chemists an always-on toxicity radar. We drop risky molecules before animal studies, saving time and budget.
— Head of Preclinical Safety, Partner R&D Team
Read full case study →
- Category
- Automation
- Tags
- Family Management, Automation, Personal Data Vault, Notifications, React, Node.js, PostgreSQL, AES-256, OCR
- Author
- Devulapelly Kushal Kumar — AI Context Engineer
- Date
- Oct 2025
- Read time
- 9 min read
- Live demo
- https://kutum.apexneural.cloud/
Summary: Kutum is a secure, intelligent family information hub that centralizes people, documents, health records, and milestones, turning them into timely nudges.
Overview
Families juggle scattered data points—documents, health records, milestones—across chats and folders. Kutum acts as a secure OS where users centralize details (sizes, passport numbers, health history) and the system handles the 'remembering'. It layers smart nudges for expiries and follow-ups, ensuring nothing falls through the cracks.
- Profiles: Unlimited
- Doc Types: 10+
- Security: AES-256
- Platform: Web/Mobile
Architecture
Modular architecture centered on three domains: People, Documents, and Health. Each flows into a centralized Notification Engine that scans for date-based triggers (expiries, birthdays, follow-ups). Authentication uses secure recovery phrases/QR codes to protect the family vault.
- Auth & Recovery: Secure access with recovery phrase and QR workflows
- People Module: Manages member profiles, attributes, and milestones
- Documents Vault: Encrypted storage with OCR and expiry tracking
- Notification Engine: Generates contextual nudges from structured dates
Features
- Family Profiles: Rich details for every member, from clothing sizes to medical history.
- Smart Document Vault: OCR-enabled storage that reads expiries and organizes by person.
- Health Timeline: Track vaccinations, visits, and vitals with follow-up reminders.
- Secure Recovery: Bank-grade recovery workflows to ensure data is never lost.
Results
- Reduced Mental Load: No more remembering dates or digging through WhatsApp.
- Better Compliance: Documents renewed on time; health follow-ups not missed.
- Secure Organization: One encrypted place for all critical family intel.
Kutum turned our family chaos into a single, calm dashboard. Passports, health records, and birthdays are finally handled before they become emergencies.
— Early Beta User, Parent of Two
Read full case study →
- Category
- Automation
- Tags
- Agentic AI, Automation, Recruitment, n8n, LLM, GPT-4, Airtable, Gmail, Google Calendar, Workflow Automation
- Author
- Akshaay — AI Context Engineer
- Date
- Nov 2025
- Read time
- 10 min read
- Live demo
- https://prism.apexneural.cloud/
Summary: End-to-end AI recruitment copilot built on n8n, OpenAI, and modern SaaS tools.
Overview
Prism turns the fragmented recruitment process into a cohesive automation layer. It listens to HR inboxes, parses resumes, uses GPT-4 to score candidates, orchestrates interview scheduling via GCal/Gmail, and even drafts final offer/rejection emails based on interviewer feedback. It replaces manual spreadsheet juggling with an intelligent, autonomous pipeline.
- Screening: 100% Auto
- Tools: n8n + 5 Apps
- Time Saved: 30min/app
- Consistency: Standardized
Architecture
Built on n8n as the central orchestrator. Workflows connect Gmail (Trigger/Comms), OpenAI (Reasoning), Airtable (State/Database), and Google Calendar (Scheduling). Webhooks facilitate handoffs between screening, analytics, scheduling, and decision stages.
- n8n Orchestrator: Low-code engine managing the 4 core workflows
- OpenAI Node: GPT-4 for resume parsing, scoring, and decision drafting
- Airtable: Structured database for candidate state and analytics
- Google Workspace: Gmail and Calendar for seamless communication
Features
- Auto-Screening: Instant resume parsing and scoring against JD.
- Smart Scheduling: Finds mutual times and handles invite logistics.
- Decision Engine: Aggregates feedback to propose final Hire/No-Hire action.
- Analytics Dashboard: Real-time view of pipeline health in Airtable.
Results
- Time Saved: Eliminated 15-30m of manual work per candidate.
- Fairness: Standardized AI scoring criteria for every applicant.
- Velocity: Zero latency handoffs between screening, scheduling, and offers.
Prism replaced a patchwork of spreadsheets and inbox digging with one coherent AI pipeline. We now spend time talking to people, not chasing info.
— Recruitment Lead, Early User
Read full case study →
- Category
- AI Systems
- Tags
- AI Recruitment, Computer Vision, HR Tech, YOLOv8, Automation
- Author
- Akshaay — AI Context Engineer
- Date
- Mar 2026
- Read time
- 10 min read
- Live demo
- https://prism.apexneural.cloud/
Summary: PRISM is an AI-powered recruitment platform that automates resume screening, interview scheduling, AI interviews, and candidate evaluation using computer vision and intelligent workflow automation.
Overview
PRISM is an end-to-end AI recruitment platform designed to solve the operational complexity HR teams face when managing large-scale hiring. Traditional hiring processes rely heavily on manual coordination across resumes, interviews, and feedback collection. PRISM replaces this fragmented system with a unified AI-driven workflow that automates resume screening, interview scheduling, AI-led screening rounds, candidate monitoring, and structured evaluation.
- Manual HR workload reduction: 85%
- Interview scheduling automation: 100%
- AI screening capacity: Unlimited candidates
- Average hiring speed improvement: 3x faster
Architecture
PRISM combines workflow automation with machine learning and computer vision to create an intelligent hiring pipeline. The system integrates resume analysis, automated scheduling, AI interviews, and behavioral monitoring into one platform.
- AI Resume Screening Engine: Uses NLP to analyze resumes against job descriptions and generate a JD Fit Score that ranks candidates automatically.
- Smart Interview Scheduling: Connects to interviewer calendars and automatically finds optimal interview slots, eliminating manual coordination.
- AI Interview Engine: Conducts conversational AI screening interviews with candidates, generating transcripts and response scoring.
- Computer Vision Monitoring System: Uses YOLOv8 and MediaPipe to track candidate behavior during interviews, monitoring face presence, gaze direction, and anomalies.
- Structured Evaluation System: Collects standardized feedback from interviewers with scoring frameworks tied directly to job requirements.
Features
- AI Resume Ranking: Automatically ranks candidates using JD fit scoring.
- AI Interview Screening: Conducts autonomous conversational interviews.
- Computer Vision Monitoring: Tracks eye movement and head direction for interview integrity.
- Automated Scheduling: Schedules interviews using real-time calendar availability.
- Offer Letter Automation: Generates and sends offers directly from the platform.
Results
- 85% Reduction in Manual HR Work: Automated resume screening, scheduling, and feedback collection eliminated repetitive administrative tasks.
- Faster Candidate Decisions: AI screening and instant scheduling reduced the time between application and decision significantly.
- Improved Hiring Quality: Structured feedback and AI candidate scoring enabled more consistent and data-driven hiring decisions.
- Interview Integrity Monitoring: Computer vision analysis detects anomalies such as multiple people in frame or excessive off-screen gaze.
PRISM removed the operational chaos from our hiring process. What used to take hours of coordination now happens automatically.
— Head of Talent, Technology Company
Read full case study →
- Category
- Agentic AI
- Tags
- RAG, Voice AI, Deepgram, OpenRouter, Cartesia, LiveKit, Speech-to-Text, Text-to-Speech, Python, FastAPI, Ollama, WebRTC
- Author
- Majeed Zeeshan — AI Context Engineer
- Date
- Nov 2025
- Read time
- 12 min read
Summary: A real-time, voice-powered Retrieval-Augmented Generation (RAG) agent that responds conversationally using speech recognition, LLM reasoning, and speech synthesis.
Overview
Traditional chatbots are limited by text-based interaction and delayed response cycles. Real-Time RAG Voice Agent solves this by merging speech input (Deepgram), instant LLM reasoning (OpenRouter), and natural voice synthesis (Cartesia), enabling latency-free, context-aware AI conversations. The agent supports both cloud (OpenRouter) and local (Ollama) setups for flexible deployment.
- Response Latency: < 500ms
- Accuracy: 98%
- Platforms Supported: Cloud & Local
- User Experience Boost: 95%
Architecture
The system uses a modular RAG pipeline optimized for real-time audio. Speech input is captured and processed by Deepgram’s Speech-to-Text engine, then routed to an OpenRouter LLM for contextual reasoning. The response is synthesized using Cartesia’s neural voice model and streamed back via LiveKit. This bidirectional streaming pipeline ensures low-latency, natural dialogue flow.
- Deepgram: Performs real-time speech-to-text transcription
- OpenRouter LLM: Generates context-driven responses using RAG-enabled models
- Cartesia: Synthesizes lifelike speech with expressive tone control
- LiveKit: Manages real-time voice sessions and WebRTC connections
- Ollama (optional): Enables local inference using Gemma or Llama models
Features
- Live Speech-to-Speech: Zero-latency conversation flow mimicking human interaction.
- Dual-Mode Intelligence: Switch between Cloud (GPT-4o) for smarts and Local (Llama 3) for privacy.
- Expressive Voice Synthesis: Cartesia integration enables emotional tone shifts (excited, calm, serious).
- RAG-Grounded Answers: Answers based on your specific knowledge base, not just generic training data.
Results
- Real-Time Conversation: Reduced response latency to sub-second levels
- Human-Like Dialogue: Enhanced voice expression using Cartesia’s tone blending
- Multi-Provider Integration: Seamlessly combined multiple AI APIs via unified orchestration
- Offline Capability: Added local inference support with Ollama for privacy-focused setups
The Voice RAG Agent felt like speaking with an actual assistant — responsive, natural, and intelligent across domains.
— Test User, Early Beta Tester
Read full case study →
- Category
- Agentic AI
- Tags
- GroundX, SOTA, OCR, Streamlit, OpenRouter, RAG
- Author
- Hansika — AI Context Engineer
- Date
- Dec 2025
- Read time
- 14 min read
- Live demo
- https://groundxdocsai.apexneural.cloud/
Summary: A high-performance document processing pipeline that leverages Ground X's SOTA parsing technology to convert complex PDFs, tables, and figures into structured, searchable intelligence.
Overview
Processing complex documents like financial reports and technical manuals is a major hurdle for RAG systems. This project implements a world-class pipeline using Ground X's X-Ray analysis. Unlike standard OCR, this system understands the relationship between figures, tables, and text, creating a rich narrative and structured JSON output. This output is then engineered into a context-aware chat interface powered by OpenRouter.
- Accuracy: SOTA
- Supported Types: PDF/DocX/Image
- Processing Speed: Real-time
- Table Detection: Advanced
Architecture
The system utilizes a Streamlit frontend for document ingestion and interactive visualization. The CORE logic is handled by Ground X for parsing and bucket management. Processed data is fetched as 'X-Ray' objects, which include narratives and keywords. These objects are used to enrich LLM prompts via OpenRouter, providing highly accurate document metadata and interactive Q&A.
- Ground X Engine: Handles high-fidelity parsing and X-Ray analysis.
- Streamlit UI: Interactive dashboard for uploads and results exploration.
- OpenRouter LLM: Orchestrates document-based Q&A and narrative synthesis.
- Bucket Management: Automated organization of raw and processed document assets.
Features
- Multi-Modal Parsing: Seamlessly handles text, tables, and images within PDFs.
- Smart Bucket Logic: Organizes documents into logical buckets for localized search contexts.
- Narrative Synthesis: Auto-generates summaries and key takeaways for instant insights.
- Visual Verification: Streamlit UI renders the original PDF alongside extracted data for trust.
Results
- Precision: Industry-leading parsing of multi-modal document layouts.
- Insight Speed: Reduces document review time by up to 80%.
- Data Richness: Extracts keywords, summaries, and structured metadata automatically.
This pipeline extracted data from our most complex multi-column tables with zero errors. It's the first time we haven't had to manually verify document parsing.
— Dr. Sarah Chen, Head of Research, BioTech Analytics
Read full case study →
- Category
- Agentic AI
- Tags
- MCP, Graphiti, Neo4j, ZepAI, Memory, Python
- Author
- Hansika — AI Context Engineer
- Date
- Oct 2025
- Read time
- 12 min read
Summary: An advanced Model Context Protocol (MCP) server leveraging Zep's Graphiti to provide persistent, graph-based memory and context continuity across multiple AI agents and platforms like Cursor and Claude.
Overview
AI agents today often suffer from 'session amnesia,' where valuable context and past interactions are lost between sessions. By implementing an MCP server that integrates with Zep's Graphiti and Neo4j, we built a memory layer that allows agents in Cursor and Claude to store, retrieve, and link information dynamically. This ensures that the agent's knowledge grows over time, leading to more accurate and personalized responses.
- Context Retention: 100%
- Database: Neo4j
- Latency: <200ms
- Model API: OpenRouter
Architecture
The architecture centers around the MCP Server acting as a bridge between AI hosts (Cursor/Claude) and a Neo4j Graph Database. Graphiti manages the extraction and persistence of memories, while OpenRouter/OpenAI handles embeddings. The server supports both SSE and stdio transports for maximum compatibility.
- MCP Server: Handles tool discovery and communication via SSE/stdio.
- Graphiti Engine: Logic layer for memory extraction and graph management.
- Neo4j Aura: Cloud-hosted graph database for persistent storage.
- MCP Hosts: Cursor and Claude Desktop as the primary AI client platforms.
Features
- Universal Memory Protocol: Standardized MCP tools ensure any compliant agent can read/write to the same memory graph.
- Entity De-duplication: Automatically merges 'Apex Neural' and 'Apex' into a single node to prevent fragmentation.
- Semantic Tagging: Auto-tags memories with concepts like 'Bug', 'Feature', or 'Architecture' for filtered retrieval.
- Visual Graph Explorer: Includes a debug UI to visualize the growing knowledge graph in real-time.
Results
- Contextual Accuracy: 40% reduction in agent hallucinations during long tasks.
- Inter-Client Sync: Seamless transition of agent state between Cursor and Claude.
- Scalability: Handles thousands of linked memories without performance degradation.
Running the Graphiti MCP server in Cursor has completely changed how I build complex apps. It remembers my previous design decisions across multiple days of work.
— Leo Valdes, Senior Fullstack Engineer
Read full case study →
- Category
- Generative AI
- Tags
- Veo3, AI Video, Generative AI, Creative AI, Video Synthesis, Google, Latent Diffusion, Prompt Engineering, Cinematography
- Author
- Vedant Pai — AI Context Engineer
- Date
- Sep 2025
- Read time
- 12 min read
Summary: A real-world case study on producing cinematic-quality AI videos using Veo 3 with minimal iteration cycles.
Overview
AI video generation has rapidly evolved, but most tools still struggle with temporal consistency, prompt adherence, and cinematic realism. This project explores how Veo 3 was used to produce high-quality video outputs efficiently, and why it proved superior to other popular models such as KlingAI, Runway Gen-2, and Pika in a production-oriented workflow.
- Prompt Iterations Reduced: 65%
- Scene Consistency: High
- Manual Fixes Needed: <10%
- Production Time Saved: 3x Faster
Architecture
The workflow was designed around Veo 3 as the core video generation engine, supported by structured prompt engineering, reference conditioning, and selective post-processing only when required.
- Prompt Design Layer: Scene-level prompts with camera, motion, and style constraints
- Veo 3 Model: Primary video generation engine
- Reference Conditioning: Visual and stylistic anchors for consistency
- Output Validation: Manual and visual checks for coherence
Features
- High-Fidelity Alignment: Adheres closely to structured prompts, preserving complex cinematic instructions.
- Low Noise Accumulation: Maintains high signal-to-noise ratio, reducing flicker and texture crawling.
- Long Context Retention: Preserves character identity and environmental layout over extended sequences.
- Robust Constraint Handling: Lower failure rate when handling multiple constraints (motion + lighting + realism).
Results
- Efficiency: Fewer prompt iterations and faster finalization
- Quality: Visually coherent, cinematic outputs
- Scalability: Easier to scale to longer narratives
Veo 3 drastically reduced the gap between AI-generated video and real cinematography. The efficiency gains were immediately noticeable.
— Internal Creative Review, Apex Neural
Read full case study →
- Category
- Computer Vision & Sports Technology
- Tags
- Computer Vision, YOLOv8, Sports Analytics, Multi-Object Tracking, Action Recognition, FastAPI, React
- Author
- Shubham Rathod — AI Context Engineer
- Date
- Oct 2025
- Read time
- 20 min read
- Live demo
- https://sportsai.apexneural.cloud/
Summary: SportsVision is a production-ready AI SaaS platform that converts raw sports match footage into structured, actionable insights using real-time computer vision and deep learning.
Overview
Manual sports video analysis is slow, subjective, and resource-intensive. Coaches often spend hours scrubbing through footage to identify key moments, player positions, and tactical patterns. SportsVision replaces this manual process with a fully automated, AI-driven pipeline that analyzes sports match footage frame-by-frame. Using multiple specialized deep learning models, the platform simultaneously tracks the ball trajectory, detects players, recognizes game actions, and segments the court. The output is a richly annotated video combined with structured performance data that coaches and analysts can immediately act upon.
- Ball Tracking Accuracy: 98.5%
- End-to-End Throughput: 30–35 FPS
- Recognized Actions: 5 Core Sports Actions
- Latency per Frame: <35 ms
- Concurrent Video Jobs: Scalable (Cloud-Native)
Architecture
SportsVision is built using a layered microservices architecture designed for scalability, modularity, and future extensibility. The React frontend communicates with a FastAPI backend via REST APIs. The backend exposes orchestration endpoints that manage video ingestion, frame extraction, inference scheduling, and output rendering. Each machine learning capability is encapsulated in an isolated service, allowing independent upgrades and experimentation without breaking the pipeline.
- Ball Tracking Module: Hybrid pipeline using YOLOv7 for ball detection combined with DaSiamRPN for temporal tracking, enabling smooth trajectory reconstruction even during occlusions and fast spikes.
- Player Detection Module: YOLOv8-based object detection model optimized for indoor court environments, providing real-time bounding boxes for all players on the court.
- Action Recognition Engine: Custom-trained YOLOv8 classifier that identifies sports-specific actions such as spike, block, serve, set, and defensive dig.
- Court Segmentation Service: RoboFlow-powered segmentation model that detects court boundaries and key zones, cached to reduce repeated inference calls.
- Pipeline Orchestrator: Central controller that coordinates frame extraction, model execution order, async inference, and annotated frame composition.
Features
- Hybrid Ball Tracking: Combines YOLO detection with temporal tracking to handle high-speed spikes and occlusions.
- Action Classification: Distinguishes between complex moves like 'Set', 'Spike', 'Block', and 'Dig'.
- Tactical Court Mapping: Maps player positions to specific zones (e.g., Zone 1-6) for positional analysis.
- Modular Pipeline: Toggle specific AI features (e.g., only ball tracking) to optimize processing interaction speed.
Results
- Time Efficiency: Reduced manual video analysis from several hours to a few minutes per match.
- High Accuracy: Achieved 98.5% ball tracking accuracy across different lighting and camera angles.
- Tactical Insights: Automatically highlights key actions and patterns for performance review.
- Scalable Deployment: Cloud-native design supports multiple concurrent users and large video workloads.
SportsVision fundamentally changed our analysis workflow. Coaches can now focus on strategy instead of manual video breakdown.
— Sports Analytics Team, Beta Testing Partner
Read full case study →
- Category
- LegalTech
- Tags
- LegalTech, LangGraph, Multi-Agent System, Google Gemini, Bilingual AI, OCR, FastAPI, Next.js, ChromaDB, SQLAlchemy
- Author
- Rahul Patil — AI Context Engineer
- Date
- Nov 2025
- Read time
- 20 min read
- Live demo
- https://legalops.apexneural.cloud/
Summary: Automated legal document processing with 15 specialized AI agents for Malaysian law firms.
Overview
The LegalOps Hub orchestrates 15 specialized AI agents across 4 distinct workflows: Intake (5 agents), Drafting (5 agents), Research (2 agents), and Evidence (3 agents). Each agent is purpose-built for a specific task in the Malaysian legal context, handling challenges like mixed Malay-English documentation, complex party name extraction, and court-specific template compliance. The system uses Google Gemini 2.0 Flash for high-speed bilingual reasoning and LangGraph for sophisticated state management across the agent swarm.\n\nThe tech stack includes: Frontend (Next.js 14 App Router, React 18, TailwindCSS, TypeScript, Zustand, Lucide React, Framer Motion), Backend (FastAPI, Python 3.11+, LangGraph, Google Gemini 2.0 Flash, ChromaDB, PostgreSQL/SQLite, SQLAlchemy, Alembic, Pytesseract, PDF2Image, LangDetect, PyPDF2), and Infrastructure (Docker, GCP, Vercel, Gunicorn).
- Total Agents: 15 Specialized
- Intake Success: 100%
- Drafting Success: 100%
- Research Success: 100%
- Evidence Success: 100%
- OCR Accuracy: 86%
- Draft Alignment: 87%
- Time Savings: ~90%
Architecture
The system is built on a modular, multi-agent architecture orchestrated by LangGraph. Each workflow (Intake, Drafting, Research, Evidence) operates as an independent graph that can be triggered via API. State is managed through 'Matter Snapshots'—structured JSON payloads that allow agents to communicate without passing massive document contexts.
- DocumentCollectorAgent: Validates and ingests files from various connectors (upload, email, drive). Handles file type validation, generates document , and creates initial matter record.
- OCRLanguageAgent: Extracts text from PDFs and images with language detection. Uses hybrid approach: PyPDF2 text extraction first for speed, falls back to Pytesseract for scanned documents. Implements per-sentence language detection using `langdetect` to handle mixed Malay/English documents. Segments text with high granularity (page/sentence level) for precise citations.
- TranslationAgent: Transfers legal text between Malay and English. Optimized execution flow often skips massive batch translation at intake to preserve original context, instead passing 'parallel texts' to case structuring. Supports bi-directional translation using Google Translate API or LLM fallback.
- CaseStructuringAgent: Parses unstructured text into a structured JSON matter snapshot. Extracts Parties (Plaintiff, Defendant), dates, amounts, and metadata. Structuring logic handles complex names and addresses typical in legal filings.
- RiskScoringAgent: Calculates a composite 1-5 complexity score. Evaluates 4 dimensions: Jurisdictional (25%), Language (30%), Volume (20%), and Time Pressure (25%). Flags matters for human review if score >= 4.0.
- IssuePlannerAgent: Identifies legal causes of action and required prayers. Analyzes matter snapshot to propose primary and alternative legal theories (e.g., Breach of Contract s.40, Negligence). Suggests specific prayers for relief mapped to verified templates. Retrieves relevant precedents to support each issue.
- TemplateComplianceAgent: Selects and enforces court-specific formatting. Retrieves correct template ID (e.g., 'TPL-HighCourt-MS-v2') based on jurisdiction (Peninsular vs East Malaysia) and court level. Ensures correct headers, intitulation, and defined terms.
- MalayDraftingAgent: Generates the primary pleading in formal Bahasa Malaysia. Uses Gemini 2.0 with strict prompting to adhere to Malaysian legal register ('Bahasa Istana/Mahkamah'). Auto-formats defined terms (PLAINTIF, DEFENDAN) and paragraph numbering (1.1, 1.2). Generates standard sections: Introduction, Facts, Breach, Relief, Prayers.
- EnglishCompanionAgent: Creates a mirror English version for reference. Generates an English 'Companion Draft' that aligns paragraph-by-paragraph with the Malay original. Does not just translate, but drafts in proper legal English to ensure conceptual equivalence.
- ConsistencyQAAgent: Validates consistency between Malay and English versions. Checks for numeral mismatches, missing dates, and proper noun spelling consistency. Returns a QA report highlighting potential discrepancies for human review.
- ResearchAgent: Searches case law databases. Integrates with CommonLII (or mock data) to find binding and persuasive authorities. Filters by court hierarchy (Federal Court > Court of Appeal > High Court).
- ArgumentBuilderAgent: Synthesizes research into a legal argument memo. Maps found cases to specific legal issues identified by the IssuePlanner. Drafts a structured legal argument (IRAC format: Issue, Rule, Analysis, Conclusion) for use in written submissions.
- TranslationCertificationAgent: Certifies documents for court submission. Generates 'Certificate of Translation' headers for non-native language documents, suitable for statutory declaration requirements.
- EvidenceBuilderAgent: Compiles the Evidence Packet. Indexes all uploaded documents, pleadings, and affidavits. Organizes them into logical sequences for the Bundle of Documents.
- HearingPrepAgent: Prepares the final Hearing Bundle and Scripts. Generates a comprehensive 4-tab Bundle (Pleadings, Submissions, Authorities, Translations). Produces bilingual 'Oral Submission Scripts' ('Skrip Hujahan Lisan') with cues for the lawyer. Includes 'If Judge Asks' section with AI-generated FAQ preparation based on case weaknesses.
Features
- DocumentCollectorAgent: Validates and ingests files from upload, email, or drive connectors.
- OCRLanguageAgent: Hybrid OCR with per-sentence language detection for mixed Malay/English docs.
- TranslationAgent: Bi-directional Malay-English translation using Google Translate or LLM.
- CaseStructuringAgent: Extracts parties, dates, and amounts into structured JSON snapshots.
- RiskScoringAgent: Computes 4-dimensional complexity score; flags matters for human review.
- IssuePlannerAgent: Proposes legal causes of action and maps them to prayers for relief.
- TemplateComplianceAgent: Selects court-specific templates (High Court vs. Lower Court).
- MalayDraftingAgent: Drafts pleadings in formal Bahasa Malaysia ('Bahasa Istana/Mahkamah').
- EnglishCompanionAgent: Creates paragraph-aligned English draft for reference.
- ConsistencyQAAgent: Validates numeral, date, and noun consistency across bilingual versions.
- ResearchAgent: Searches case law (CommonLII) and filters by court hierarchy.
- ArgumentBuilderAgent: Synthesizes IRAC-format legal arguments for written submissions.
- TranslationCertificationAgent: Generates 'Certificate of Translation' headers for court submission.
- EvidenceBuilderAgent: Compiles and indexes all documents into the Bundle of Documents.
- HearingPrepAgent: Generates 4-tab Hearing Bundle, Oral Scripts, and 'If Judge Asks' FAQs.
Results
- Functional Agents: 12 of 15 agents fully operational (80% overall success rate).
- Intake Workflow: 100% success rate for document ingestion and OCR.
- Drafting Workflow: 100% success rate for bilingual pleading generation.
- Research Workflow: 100% success rate for case law search and argument synthesis.
- Evidence Workflow: 100% success rate (TypeError in bundling logic pending fix).
- Bilingual Alignment: 87% average alignment between Malay and English drafts.
- OCR Confidence: 86% accuracy on scanned PDF documents.
- Risk Score Baseline: Average complexity: 1.25/5.0 (low baseline in testing).
Reduces time-to-first-draft by approximately 90%. Transforms the manual process of cross-referencing documents and translating legal terms into a unified, instant workflow. Enables junior lawyers to handle complex cases with AI guardrails.
— LegalOps Hub Team, Internal Engineering Assessment
Read full case study →
- Category
- InsurTech AI
- Tags
- Agentic AI, RAG, Healthcare, InsurTech, Automated Audit, FastAPI, LangGraph, PGVector, Multi-Agent, PostgreSQL, React, OCR, Claims Processing
- Author
- Ramya — Senior Engineer - Integrations and Applied AI
- Date
- Dec 2025
- Read time
- 15 min read
Summary: A production-ready autonomous multi-agent system that audits health insurance claims against complex policy documents using RAG, detecting revenue leakage with 99% accuracy.
Overview
Health insurance claims processing is one of the most operationally heavy and error-prone tasks in the industry. Manual auditors often miss subtle policy exclusions buried in 50-page documents. RecoveryCopilot solves this by deploying a team of autonomous agents that read claim documents, extract structured medical data, and cross-reference every line item against vector-embedded policy documents to instantly find overpayments and violations.\n\nHow It Helps: RecoveryCopilot transforms the claims department from a cost center to a value recovery engine. It eliminates the backlog of unaudited claims and ensures 100% policy compliance without adding headcount. Benefits include: Auditing 100% of claims (vs 5-10% manual sample), reducing leakage from overpayments and unapplied limits, standardizing decision making across all claim types, freeing up senior auditors to focus on complex fraud cases, and providing instant feedback to hospitals on rejection reasons.
- Audit Speed: <30s/claim
- Recovery Found: $2.5M+
- Accuracy: 98.5%
- Manual Effort Reduction: 90%
Architecture
The platform operates on a Hub-and-Spoke architecture. The Supervisor Agent acts as the central brain, dispatching tasks to worker agents via an event bus. State is persisted in PostgreSQL, while policy documents are chunked and stored in PGVector for high-speed semantic retrieval.
- Supervisor Agent: Orchestrates workflow, manages agent lifecycle, and implements self-healing logic to automatically restart failed sub-agents.
- Policy RAG Engine: PGVector storage for semantic policy search. Retrieves specific policy clauses relevant to a claim's diagnosis and treatment using vector search.
- Recovery Agent: LLM-powered adjudication logic for complex rules (e.g., 'Room Rent Capping', 'Co-pay Logic') that simple lookups cannot handle.
- Extractor Agent: Structured entity extraction from unstructured OCR text. Pulls structured data like Dates, Amounts, and Medical Codes.
- Unified FastAPI Gateway: API gateway for document ingestion, claim submission, and reporting dashboard endpoints.
Features
- Autonomous Policy RAG: Retrieves specific policy clauses relevant to a claim's diagnosis using semantic vector search.
- Multi-Agent Orchestration: Specialized agents for OCR, Classification, Extraction work in parallel with Supervisor fault tolerance.
- Intelligent Recovery Detection: LLM-based adjudication for 'Room Rent Capping', 'Co-pay Logic', and complex rules.
- Self-Healing Workflows: Supervisor agent automatically restarts failed sub-agents and manages state consistency.
- Automated Case Linking: Links related claims by Patient ID and IP number to detect duplicate or split-claim fraud.
Results
- Speed: Reduced processing time by 90%, auditing claims in under 30 seconds.
- Accuracy: Surpassed human-level auditing accuracy with 98.5% precision.
- Scale: Easily handles peak-season volumes of 10k+ claims/day.
- Recovery: Identified $2.5M+ in recoverable overpayments.
The system caught a $50k room rent violation on its first day of pilot. It pays meticulous attention to policy details that humans simply can't match at speed.
— Claims VP, Leading Health Insurer
Read full case study →
- Category
- Agentic AI
- Tags
- Agentic AI, Documentation, Hybrid LLM, Python, Next.js, FastAPI, Automation, CrewAI, LM Studio, DeepSeek, GPT-4o Mini, GitHub
- Author
- Ramya — Senior Engineer - Integrations and Applied AI
- Date
- Dec 2025
- Read time
- 20 min read
Summary: An intelligent hybrid AI documentation platform combining local LLMs with cloud AI to automatically generate comprehensive, publication-ready documentation from any GitHub repository.
Overview
Technical documentation is essential but time-consuming, often taking weeks per project and requiring constant updates. This platform solves this challenge with a hybrid AI approach: using local LLMs (LM Studio with DeepSeek-R1) for analysis and planning at zero API cost, while leveraging cloud LLMs (OpenAI GPT-4o-mini) only for final polished writing. The system features a multi-agent crew that analyzes codebases, creates embeddings, plans structure, writes documentation, and performs quality checks—all automatically from a GitHub URL.\n\nHow It Helps: This platform eliminates the documentation bottleneck that slows down software projects. Engineers spend less time writing docs and more time coding. Documentation stays current because regeneration takes minutes, not weeks. The hybrid architecture ensures professional quality output while keeping costs minimal. Teams can generate docs on-demand for any repository, support multiple projects simultaneously, and maintain consistency across all documentation.
- Documentation Quality: 98%
- Time Reduction: 95%
- Cost per Generation: $0.10-0.50
- Generation Speed: 10-20 sec
Architecture
The system uses a hybrid hub-and-spoke architecture where a CrewAI orchestrator coordinates specialized agents. Local agents (running on LM Studio DeepSeek-R1-1.5B) handle compute-intensive analysis, embedding creation, and quality checks. Cloud agents (OpenAI GPT-4o-mini) focus on final documentation writing where language quality is critical. The FastAPI backend exposes REST endpoints, while the Next.js frontend provides an intuitive interface with real-time updates.
- FastAPI Backend: REST API server with CORS, health checks, and extended timeouts for long-running documentation tasks.
- CrewAI Orchestrator: Coordinates agent execution, manages state, and orchestrates the complete documentation workflow.
- Local Agents (LM Studio): CodebaseAnalyzer, EmbeddingAgent, PlannerAgent, QualityCheckAgent running on DeepSeek-R1-1.5B at zero cost.
- Cloud Agent (OpenAI): WriterAgent using GPT-4o-mini for generating polished, publication-ready documentation.
- Preprocessor: Python-based code parser that identifies important files without LLM calls for faster processing.
- Next.js Frontend: Modern React UI with TailwindCSS, markdown preview, syntax highlighting, and export functionality (PDF, Markdown, HTML).
Features
- Hybrid LLM Architecture: Routes tasks between local LLMs (free) and cloud LLMs (paid) to optimize cost and quality.
- Dual Pipeline Modes: Comprehensive 7-step pipeline or optimized 5-step pipeline for 10-20 second execution.
- GitHub-Native Integration: Automatic cloning, analysis, and documentation from any GitHub URL.
- Multi-Agent Orchestration: CrewAI coordinates CodebaseAnalyzer, EmbeddingAgent, PlannerAgent, WriterAgent, QualityCheckAgent.
- Repository-Specific Storage: Organized output files (SUMMARY.md, STRUCTURE.md, COMPONENTS.md, FINAL_DOCUMENTATION.md).
- Modern Web Interface: Next.js frontend with real-time progress, markdown preview, syntax highlighting, and export options.
- Production-Ready API: FastAPI backend with CORS, health checks, extended timeouts, and automatic port selection.
- Cost Optimization: 90% of LLM calls run locally at zero cost. Only final polishing uses paid cloud API.
Results
- Speed: Documentation generation in 10-20 seconds (optimized) or 5-15 minutes (comprehensive).
- Cost: 90% cost reduction vs cloud-only LLM solutions, $0.10-0.50 per generation.
- Quality: 98% documentation quality score with polished, publication-ready output.
- Adoption: Successfully deployed for 20+ repositories with consistent results.
We used to spend 2-3 weeks documenting each new service. Now we generate comprehensive docs in under 30 seconds. The quality is on par with our best technical writers.
— Engineering Manager, Platform Engineering Lead
Read full case study →
- Category
- Agentic AI
- Tags
- MCP, Streamlit, Multi-Modal, RAG, Web Scraping, Python, Firecrawl, Ragie, OpenRouter, GPT-4o Mini, LangChain
- Author
- Ramya — Senior Engineer - Integrations and Applied AI
- Date
- Oct 2025
- Read time
- 16 min read
- Live demo
- https://mcpnexus.apexneural.cloud
Summary: A powerful Streamlit-based AI assistant that leverages the Model Context Protocol (MCP) to orchestrate multiple specialized AI servers for web scraping, multimodal RAG, and intelligent information retrieval.
Overview
Modern AI applications require integration with multiple specialized services to deliver comprehensive functionality. The Ultimate AI Assistant demonstrates a production-ready approach to building modular AI systems using the Model Context Protocol (MCP). By orchestrating Firecrawl for intelligent web scraping and Ragie for multimodal Retrieval-Augmented Generation, this platform enables users to interact naturally with powerful AI capabilities through a simple conversational interface built with Streamlit.\n\nHow It Helps: This platform empowers developers and organizations to rapidly build AI assistants with specialized capabilities. By leveraging MCP, teams can integrate best-in-class services for web scraping, RAG, and other functions without building everything from scratch. The conversational interface makes advanced AI accessible to non-technical users.
- Integration Time: <30 min
- MCP Servers: 2+
- Query Response: <5 sec
- User Config: JSON-based
Architecture
The system follows a modular architecture where a central MCP Agent orchestrates multiple specialized MCP servers. The Streamlit frontend provides the user interface, which communicates with an MCPAgent that manages tool selection and execution. Each MCP server (Firecrawl, Ragie) runs as an independent process, communicating via the standardized Model Context Protocol.
- Streamlit Frontend: Provides conversational UI and configuration management for user interactions.
- MCP Agent: Core orchestrator that routes queries to appropriate MCP servers based on user intent.
- Firecrawl Server: Handles intelligent web scraping and content extraction tasks via MCP protocol.
- Ragie Server: Manages multimodal RAG and semantic search operations for document retrieval.
- OpenRouter LLM: Provides natural language understanding and high-quality response generation (GPT-4o-mini).
Features
- Model Context Protocol Integration: Standardized LLM-to-tools communication enabling flexible and extensible AI workflows.
- Firecrawl Web Scraping: Intelligent web scraping and content extraction through natural language requests.
- Ragie Multimodal RAG: Semantic search and retrieval across text, images, and documents with high accuracy.
- Streamlit Chat Interface: Intuitive conversational UI making advanced AI capabilities accessible to all users.
- Flexible Configuration: JSON-based MCP server configuration without code changes for rapid experimentation.
- OpenRouter LLM Integration: Access to state-of-the-art language models like GPT-4o-mini for high-quality responses.
Results
- Development Speed: Reduced AI assistant development time by 80%.
- Flexibility: Easy to swap or add new MCP servers as needs evolve.
- User Adoption: Natural language interface increased usage by 3x.
This MCP-based architecture allowed us to build a production AI assistant in days instead of months. The ability to seamlessly integrate Firecrawl and Ragie through a unified protocol was transformative.
— Michael Chen, Director of AI, TechVentures
Read full case study →
- Category
- Multimodal AI Systems
- Tags
- Multimodal AI, Cross-Modal Generation, Audio, Image, Video, Text, AI Orchestration, Python, Generative AI, Semantic Latent Space
- Author
- Vedant Pai — AI Context Engineer
- Date
- Nov 2025
- Read time
- 20 min read
Summary: A production-grade multimodal system that enables seamless conversion between audio, image, text, and video using a unified latent representation.
Overview
Traditional AI systems treat audio, image, text, and video as isolated domains. This fragmentation introduces friction when building real-world products that require seamless transformation between modalities. AITV addresses this limitation by introducing a unified cross-modal architecture that allows any modality—audio, image, text, or video—to be converted into any other modality through a shared semantic representation.
- Supported Modalities: 4 (Audio, Image, Text, Video)
- Conversion Paths: 12+
- Semantic Retention: High
- Pipeline Modularity: Fully Decoupled
Architecture
AITV is built around a hub-and-spoke multimodal architecture. All incoming modalities are first encoded into a shared semantic latent space. From this unified representation, specialized decoders generate the target modality. This avoids lossy chained conversions and enables true cross-compatibility.
- Modality Encoders: Dedicated encoders for audio, image, text, and video that transform raw inputs into a normalized semantic latent representation.
- Shared Semantic Latent Space: A modality-agnostic representation capturing intent, structure, and meaning independent of source format.
- Modality Decoders: Specialized generators that transform the shared latent representation into the target modality.
- Cross-Modal Orchestrator: Controls routing, validation, and transformation logic between encoders and decoders.
- Validation & Consistency Layer: Ensures semantic integrity and detects information loss during conversion.
Features
- Any-to-Any Modality Conversion: Convert between audio, image, text, and video seamlessly through a unified semantic representation.
- Shared Semantic Latent Space: A modality-agnostic representation that preserves meaning and intent across all transformations.
- Decoupled Architecture: Independent encoders and decoders that can be updated or replaced without affecting other components.
- Semantic Validation: Built-in consistency checks that detect and prevent information loss during conversion.
- Production Observability: Comprehensive monitoring, logging, and fault isolation for reliable production deployments.
Results
- Cross-Compatibility: Any modality can be converted to any other without restructuring the pipeline.
- Semantic Consistency: Meaning and intent are preserved across transformations.
- Scalability: New modalities can be added without rearchitecting the system.
AITV fundamentally changed how we approach multimodal content pipelines. Converting between audio, video, and text is now seamless and reliable.
— Engineering Lead, Content Platform Team
Read full case study →
- Category
- Agentic AI
- Tags
- RAG, Vector Database, Multi-Modal AI, Python, Streamlit, LangGraph
- Author
- Ramya — Senior Engineer - Integrations and Applied AI
- Date
- Nov 2025
- Read time
- 20 min read
- Live demo
- https://notebooklm.apexneural.cloud/
Summary: An open-source implementation of Google's NotebookLM that grounds AI responses in your documents with accurate citations, featuring multi-modal processing, conversational memory, and AI podcast generation.
Overview
Document-based AI assistants often struggle with accuracy and citation. Users need to trust AI responses, especially when working with critical documents like research papers, legal documents, or technical manuals. This project builds an open-source NotebookLM clone that ensures every AI response is grounded in source documents with precise citations. The system processes multiple document types (PDFs, audio, video, web content), maintains conversational context through temporal knowledge graphs, and even generates AI podcasts from documents.
- Citation Accuracy: 100%
- Document Types: 7+
- Processing Speed: Real-time
- Memory Retention: Full Context
Architecture
The system follows a modular RAG (Retrieval-Augmented Generation) architecture with a Streamlit frontend orchestrating specialized processing components. Each component handles a specific document type or processing stage, all connected through a central vector database and memory layer for unified semantic search and context retention.
- Document Processor: PyMuPDF-based processing for PDF, TXT, and Markdown files with metadata extraction
- Audio Transcriber: AssemblyAI integration for audio transcription with speaker diarization
- YouTube Transcriber: Video-to-text conversion with timestamp-based chunking
- Web Scraper: Firecrawl-powered content extraction from websites
- Embedding Generator: Local HuggingFace model for vector embeddings generation
- Qdrant Vector DB: Efficient vector storage and semantic search with citation metadata
- RAG Generator: OpenRouter LLM integration for cited response generation
- Memory Layer: Zep temporal knowledge graphs for conversational context
- Podcast Generator: Script generation and Coqui TTS for multi-speaker podcast creation
Features
- Multi-Modal Document Processing: Process PDFs, text files, markdown, audio recordings, YouTube videos, and web pages seamlessly with PyMuPDF, AssemblyAI, and Firecrawl integration.
- Citation-First AI Responses: Every claim is backed by specific sources with page numbers, timestamps, and clickable references - ensuring verifiable and trustworthy answers.
- Temporal Knowledge Graphs: Zep-powered memory layer maintains conversational context across sessions using temporal knowledge graphs for intelligent context retention.
- Vector-Based Semantic Search: Qdrant vector database enables efficient semantic search across all documents with metadata-rich retrieval for precise citation.
- AI Podcast Generation: Transform documents into engaging multi-speaker podcast conversations using script generation and open-source Coqui TTS.
- Authentication & User Management: FastAPI backend with JWT-based authentication ensures secure access and user-specific document management.
Results
- Accuracy: 100% citation traceability to source documents
- Efficiency: 3x faster document review and analysis
- Versatility: Supports 7+ document formats seamlessly
- Memory: Temporal knowledge graphs remember full context
NotebookLM Clone transformed how our research team works with academic papers. The citation accuracy and multi-modal support means we can process interviews, papers, and conference videos all in one place.
— Dr. Sarah Mitchell, Research Lead, AI Labs
Read full case study →
- Category
- Agentic AI
- Tags
- CrewAI, Financial AI, Real-Time Streaming, Portfolio Management, React, FastAPI
- Author
- Ramya — Senior Engineer - Integrations and Applied AI
- Date
- Oct 2025
- Read time
- 16 min read
- Live demo
- https://stockpilot.apexneural.cloud/
Summary: An intelligent AI agent that streams portfolio analysis workflows in real-time, enabling users to watch as it fetches stock data, calculates allocations, and generates investment insights live.
Overview
Understanding investment decisions requires transparency into how analyses are performed. Traditional portfolio tools provide results but hide the process, leaving investors uncertain about how recommendations are generated. This project builds an autonomous AI agent that not only analyzes stock portfolios but streams every step of its workflow in real-time—from data fetching to allocation calculations to insight generation—giving users complete visibility into the decision-making process.
- Processing Speed: < 3 sec
- Real-time Updates: 100%
- Data Accuracy: 99.8%
- User Transparency: Full Visibility
Architecture
The system follows a layered architecture with clear separation between frontend UI, communication protocol, backend orchestration, and data sources. The AG-UI Protocol acts as the bridge, enabling real-time event streaming from the CrewAI workflow to the React frontend.
- React/Next.js Frontend: Modern UI with CopilotKit integration for seamless agent interaction
- AG-UI Protocol Layer: Handles real-time bidirectional communication and state synchronization
- FastAPI Backend: High-performance API server managing workflow execution and data flow
- CrewAI Flow Engine: Orchestrates multi-step analysis workflow with state management
- yfinance + pandas: Fetches and processes historical stock data from Yahoo Finance API
Features
- Real-Time Workflow Streaming: Users watch live as the agent processes queries, fetches data, and performs calculations through the AG-UI Protocol, providing unprecedented transparency.
- Intelligent Query Processing: AI-powered natural language understanding extracts ticker symbols, investment amounts, dates, and strategies from conversational user input.
- Multi-Strategy Support: Supports both single-shot investing and dollar-cost averaging (DCA) strategies with automatic simulation and comparison.
- SPY Benchmark Comparison: Automatically compares portfolio performance against the S&P 500 (SPY) benchmark to provide context for investment returns.
- Bull/Bear Insights Generation: AI generates balanced positive and negative insights for each investment, helping users understand both opportunities and risks.
- Additive Portfolio Management: Intelligently adds new investments to existing portfolios without replacement, maintaining portfolio history and continuity.
Results
- Transparency: 100% visibility into every calculation and decision
- Speed: Complete portfolio analysis in under 3 seconds
- Education: Users learn investment concepts through observation
- Trust: Real-time streaming builds confidence in AI recommendations
Watching the AI work through each step of the analysis was eye-opening. I finally understand how my portfolio allocations are calculated and why certain stocks perform differently.
— Jessica Chen, Individual Investor
Read full case study →
- Category
- Agentic AI
- Tags
- Agentic AI, Multi-Agent Systems, CrewAI, MCP, LLM Orchestration, Python, Streamlit
- Author
- Hansika — AI Context Engineer
- Date
- Dec 2025
- Read time
- 12 min read
- Live demo
- https://researcherai.apexneural.cloud
Summary: An MCP-powered multi-agent research platform that performs deep web research, analysis, and report generation using autonomous AI agents.
Overview
Traditional research workflows require manual search, reading, synthesis, and report writing, making them slow and inconsistent. The Agentic Deep Researcher automates this entire pipeline using specialized AI agents that collaborate to search the web, analyze content, and generate structured research reports with citations.
- Research Speed: 5x Faster
- Manual Effort Reduced: 80%
- Agent Collaboration: 3 Core Agents
Architecture
The system follows a layered agentic architecture where a central orchestrator coordinates multiple specialized agents. An API router connects the UI, agents, memory, and external services such as LinkUp and OpenRouter.
- Streamlit Frontend: User interface for submitting research queries
- Agent Orchestrator: Coordinates agent execution and workflow state
- Web Search Agent: Fetches relevant information using LinkUp API
- Research Analyst Agent: Analyzes and synthesizes retrieved data
- Technical Writer Agent: Generates structured reports with citations
- Memory System: Stores intermediate context and agent state
Features
- Multi-Agent Research Workflow: Specialized agents handle search, analysis, and writing tasks collaboratively.
- Deep Web Search: Uses LinkUp API to retrieve high-quality, relevant web sources.
- MCP Server Integration: Exposes the system as an MCP tool usable in Cursor and other MCP clients.
- Interactive UI: Streamlit-based interface allows users to submit queries and view structured reports.
- Flexible LLM Support: Supports multiple LLMs via OpenRouter for cost and performance optimization.
Results
- Speed: Research tasks completed 5x faster
- Consistency: Structured outputs with reliable citations
- Scalability: Supports multiple concurrent research requests
This system turned hours of manual research into a few minutes of structured insights.
— Internal Engineering Team, AI Platform Users
Read full case study →
- Category
- AI Automation
- Tags
- AI Nudges, Predictive Notifications, Family Automation, Contextual AI, Smart Reminders, NLP
- Author
- Devulapelly Kushal Kumar — AI Context Engineer
- Date
- Nov 2025
- Read time
- 14 min read
- Live demo
- https://kutum.apexneural.cloud/
Summary: A context-aware AI notification engine that transforms static family data into proactive, human-centric nudges—reminding families about passport renewals, health follow-ups, and life milestones at precisely the right moment.
Overview
Traditional reminders are binary: 'Passport expires on X date'. But families need more—they need context. The Kutum AI Nudges Engine doesn't just store expiry dates; it understands the semantic meaning behind them. When Dad's passport expires in 6 months, the system knows that Indian passport renewal takes 4-6 weeks, so it nudges 3 months before with 'Dad's passport expires in 6 months—time to start the renewal process'. This semantic layer transforms raw database dates into actionable, human-centric assistance.\n\nThe engine operates across three core domains: Documents (passports, IDs, policies), Health (medications, follow-ups, vaccinations), and Life Events (birthdays, anniversaries, school admissions). Each domain has its own intelligence layer that considers lead times, dependencies, and real-world constraints. The result? Families never miss a renewal, never forget a follow-up, and never scramble at the last minute.\n\nWe built this because generic notification apps fail families. They don't understand that a driver's license renewal in India needs an appointment weeks in advance, or that a child's school admission requires documents to be gathered months before. The AI Nudges Engine encodes this real-world knowledge into its recommendation system.
- Nudge Types: 25+
- Lead Time Rules: 50+
- Context Variables: 15+
- Delivery Channels: 3
Architecture
The AI Nudges Engine follows a layered architecture with four primary components: the Data Layer (unified family graph), the Intelligence Layer (rule engine + ML predictor), the Scheduling Layer (optimal timing), and the Delivery Layer (multi-channel notifications). Each nudge passes through a semantic enrichment pipeline that adds context, urgency, and actionable next steps.
- Family Data Graph: Unified graph connecting members, documents, health records, and events with temporal metadata and relationship edges.
- Semantic Rule Engine: Domain-specific rules encoding lead times, dependencies, and regional constraints (e.g., passport renewal timelines vary by country).
- Context Enrichment Pipeline: NLP-powered layer that transforms raw notifications into human-readable, actionable nudges with personalized language.
- Optimal Timing Scheduler: Determines the best time to deliver nudges based on urgency, user engagement patterns, and notification fatigue prevention.
- Multi-Channel Delivery: Push notifications, in-app alerts, and email digests with preference-based routing and fallback logic.
- Feedback Loop Engine: Tracks nudge engagement (opened, snoozed, acted upon) to improve future timing and relevance.
Features
- Semantic Nudge Generation: Transforms raw expiry dates into context-rich, actionable notifications with personalized language and direct links to actions.
- Four-Tier Urgency Model: Critical, High, Medium, and Low urgency levels with distinct notification behaviors and snooze options.
- Smart Bundling: Groups related nudges to prevent notification overload and improve action efficiency.
- Family Graph Sharing: Shared nudges for documents and events that require multiple family members' attention.
- Timing Optimization: Learns user engagement patterns to deliver nudges at the optimal time for each individual.
- Regional Intelligence: Encodes local knowledge about government processes, healthcare schedules, and compliance timelines.
- Multi-Channel Delivery: Push notifications, in-app alerts, email digests, and SMS fallback for critical nudges.
- Notification Fatigue Prevention: Daily caps, quiet hours, and digest modes to ensure nudges remain valuable, not annoying.
Results
- Zero Missed Renewals: Beta users reported 0 missed document renewals after 6 months of use, compared to an average of 2-3 panic situations per year previously.
- 85% Reduction in Mental Load: Users no longer maintain mental checklists or multiple calendar entries. The system handles temporal awareness automatically.
- 3x Faster Action: Average time from nudge to action reduced from 3 days to same-day, thanks to actionable context and direct links.
- 95% Nudge Relevance Score: User feedback showed 95% of nudges were rated 'useful' or 'very useful', with minimal notification fatigue.
The difference between Kutum and a calendar app is night and day. Calendar apps tell me 'Passport expires June 15'. Kutum tells me 'Dad's passport expires in 6 months—I've added the Passport Seva Kendra link and the documents checklist'. That's the difference between a reminder and actual help.
— Early Beta Tester, Family of 5 – Managing 15+ Documents
Read full case study →
- Category
- AI/ML
- Tags
- OCR, Document AI, Computer Vision, Tesseract, GPT-4 Vision, Data Extraction, Family Documents
- Author
- Devulapelly Kushal Kumar — AI Context Engineer
- Date
- Dec 2025
- Read time
- 16 min read
- Live demo
- https://kutum.apexneural.cloud/
Summary: A multi-model OCR pipeline that automatically extracts, validates, and structures information from family documents—passports, Aadhaar cards, health reports, and insurance policies—with 98%+ accuracy.
Overview
Families accumulate dozens of critical documents—passports, driver's licenses, Aadhaar cards, insurance policies, medical reports, vehicle registrations. Traditionally, users must manually enter every detail: name, document number, expiry date, issued date. This friction causes most users to abandon the process or enter incomplete data.\n\nThe Kutum OCR system eliminates this friction entirely. Users simply photograph their documents (even at an angle, even in poor lighting), and the AI extracts structured data automatically. A passport photo becomes a complete record: holder name, passport number, issue date, expiry date, place of issue, and nationality—all extracted and validated in under 3 seconds.\n\nThe Technical Challenge: Indian documents present unique OCR challenges. Aadhaar cards have QR codes with embedded data. Passports use MRZ (Machine Readable Zone) with specific encoding. Health reports come from thousands of different labs with varied formats. Insurance policies are dense PDFs with nested tables. We built a multi-model pipeline that selects the optimal extraction strategy per document type.
- Document Types: 15+
- Extraction Accuracy: 98.2%
- Processing Time: <3 sec
- Supported Formats: JPG, PNG, PDF
Architecture
The OCR pipeline follows a four-stage architecture: Image Preprocessing (enhancement, deskewing, noise reduction), Document Classification (identifying document type), Specialized Extraction (type-specific OCR and parsing), and Validation & Structuring (field validation and schema mapping). The system uses a hybrid approach—Tesseract for general text, Google Vision API for complex layouts, and GPT-4 Vision for semantic understanding of unstructured documents.
- Image Preprocessor: OpenCV-based enhancement pipeline: auto-rotation, deskewing, contrast normalization, noise reduction, and perspective correction for angled photos.
- Document Classifier: CNN-based classifier trained on 15+ document types. Identifies passport, Aadhaar, PAN, license, health report, insurance policy, etc. with 99.5% accuracy.
- MRZ Parser: Specialized parser for Machine Readable Zones on passports and visas. Extracts encoded data with checksum validation.
- QR Decoder: Extracts and decrypts data from Aadhaar QR codes, providing cryptographically verified identity information.
- GPT-4 Vision Extractor: For complex/unstructured documents (health reports, policies), uses Vision LLM to semantically understand and extract relevant fields.
- Validation Engine: Cross-validates extracted data using checksums, format rules, and dependency checks (e.g., expiry date must be after issue date).
Features
- Multi-Model OCR Pipeline: Intelligent routing between Tesseract, Google Vision API, and GPT-4 Vision based on document type and complexity.
- 15+ Document Types: Supports passports, Aadhaar, PAN, licenses, health reports, insurance policies, and more with type-specific extraction.
- MRZ & QR Parsing: Specialized parsers for machine-readable zones (passports) and cryptographically signed QR codes (Aadhaar).
- Image Preprocessing: Auto-rotation, deskewing, contrast normalization, and shadow removal for poor-quality photos.
- Confidence Scoring: Field-level confidence scores with visual indicators for user verification.
- Semantic Health Report Extraction: GPT-4 Vision understands varied lab report formats, extracting test names, values, and reference ranges.
- Privacy-First Design: On-device preprocessing, ephemeral cloud processing, and encrypted storage.
- Continuous Learning: User corrections are logged to improve future extraction accuracy.
Results
- 98.2% Extraction Accuracy: Across 15+ document types, the system achieves 98.2% field-level accuracy with confidence scoring.
- 95% Reduction in Data Entry Time: Average document entry time reduced from 3-5 minutes to <15 seconds including user confirmation.
- 4x More Documents Uploaded: Beta users uploaded 4x more documents compared to the manual-entry-only version, thanks to reduced friction.
- Zero Data Loss from Poor Photos: Preprocessing pipeline recovers usable data from 92% of initially 'poor quality' images.
I photographed my dad's passport at an angle, in low light, and Kutum extracted everything perfectly—name, number, expiry date, even the place of issue. What would have taken me 5 minutes of typing happened in 3 seconds. This is the future of family document management.
— Beta User, Managing Documents for 4-Person Family
Read full case study →
- Category
- Automation
- Tags
- FastAPI, SaaS, Boilerplate, Multi-tenant, Python
- Author
- Likhith Kumar Masura — AI Context Engineer
- Date
- Sep 2025
- Read time
- 5 min read
- Live demo
- https://apexsaaskit.apexneural.cloud/
Summary: Build production-ready SaaS applications in minutes, not months.
Overview
Apex SaaS Framework is a comprehensive FastAPI boilerplate designed to eliminate the repetitive setup work required for modern SaaS applications. It provides a robust foundation with pre-configured authentication, multi-tenancy, and payment integration, allowing developers to focus purely on business logic.
- Setup Time: < 2 min
- Boilerplate Reduction: 90%
- Test Coverage: 100%
Architecture
The framework follows a strict Clean Architecture pattern, ensuring separation of concerns and long-term maintainability. It leverages FastAPI for the interface layer, SQLAlchemy 2.0 for the persistence layer, and a domain-centric core that isolates business rules from external frameworks.
- API Layer: FastAPI routers and Pydantic schemas handling HTTP requests.
- Domain Layer: Pure Python business logic, services, and repository interfaces.
- Infrastructure: Concrete implementations for Database, Email, and Storage adapters.
- Core Security: Centralized authentication, RBAC, and configuration management.
Results
- Rapid Development: Launch complete SaaS backends with auth and payments in minutes.
- Enterprise Ready: Built-in RBAC and multi-tenancy support complex organizational structures.
- Maintainable: Clean Architecture prevents codebase spaghetti as the application grows.
Apex allowed us to ship our MVP in two weeks instead of three months. The architecture is rock solid.
— Sarah Chen, CTO, FinFlow
Read full case study →
- Category
- Automation
- Tags
- Knowledge Engineering, AI Content, SaaS, Education, Python
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Oct 2025
- Read time
- 5 min read
- Live demo
- https://bookgen.apexneural.cloud/
Summary: Democratizing founder knowledge through AI-driven content generation.
Overview
DBaaS E-Books is a knowledge distribution engine designed to bridge the gap between complex technical concepts and actionable business execution. Powered by the Tale-weaver core, it dynamically generates structured educational content—from EPUBs to PDFs—teaching founders how to discover ideas, validate markets, and execute builds. It transforms raw knowledge into distinct, consumable learning paths.
- Coverage: Idea to Launch
- Depth: Practical
- Audience: Founders & Builders
Architecture
The system utilizes a modular backend service (`Tale-weaver`) to orchestrate content generation. It decouples the writing tone, genre structure, and output formatting (EPUB/PDF) from the core content logic. This allows for dynamic re-packaging of knowledge into various formats suitable for e-readers or print.
- Content Engine: Core logic handling genre selection, tone adjustment, and chapter outlining.
- Format Service: Python-based renderer (`ebooklib`, `reportlab`) converting text to professional layouts.
- Metadata Layer: Injects author bios, synopses, and semantic tagging for specialized outputs.
- AI Orchestrator: Drives the narrative flow ensuring consistency across multi-chapter volumes.
Results
- Actionable Knowledge: Readers move from theory to practice with step-by-step validation frameworks.
- Rapid Dissemination: New best practices are instantly compiled and distributed to the community.
- Standardized Success: Provides a common lexicon and methodology for the entire DBaaS ecosystem.
The structured approach to idea validation saved us months of aimless building. It's like having a co-founder in book form.
— Elena Rodriguez, SaaS Builder
Read full case study →
- Category
- Automation
- Tags
- EdTech, AI, Automation, DBaaS
- Author
- Shubham Rathod — AI Context Engineer
- Date
- Nov 2025
- Read time
- 5 min read
- Live demo
- https://course.apexneural.cloud/
Summary: Transforming technical documentation into structured, multi-modal learning experiences.
Overview
DBaaS E-Courses bridge the gap between complex platforms and user mastery. We built a system that autonomously generates structured learning paths, converting raw documentation into valid Google Slides presentations, neural audio lectures, and interactive quizzes. This ensures that every founder and builder on the DBaaS platform has access to high-quality, up-to-date education.
- Skill Coverage: Idea to Launch
- Learning Level: Beginner to Advanced
- Hands-On Focus: High
Architecture
The solution orchestrates a pipeline of AI services. A FastAPI backend manages the course lifecycle, interfacing with OpenAI for content generation and Piper TTS for audio. The frontend provides a seamless creation wizard, while the Google Slides API handles the visual rendering of educational material.
- FastAPI Backend: Manages the course lifecycle and orchestrates the pipeline of AI services.
- Frontend Application: Provides a seamless creation wizard for course generation.
- LLM Content Generation: Generates structured course content and lesson scripts using OpenAI GPT-4o.
- Text-to-Speech Service: Converts lesson scripts into neural audio lectures using Piper TTS.
- Slides Rendering Service: Handles the visual rendering of educational material using Google Slides API.
Results
- Accelerated Production: Reduced course creation time significantly.
- Consistent Quality: Standardized educational structure across all topics.
- Multi-Modal Delivery: Automatic generation of slides, audio, and text.
What takes weeks of manual work now happens in minutes. From course design to final video export, we automate the entire process.
— Apex Neural Team, Platform Capability
Read full case study →
- Category
- Automation
- Tags
- React, AI, Market Research, Generative UI, SaaS
- Author
- Likhith Kumar Masura — AI Context Engineer
- Date
- Dec 2025
- Read time
- 6 min read
- Live demo
- https://dbaas.apexneural.cloud/search
Summary: Launch your digital business with AI-assisted market research and instant landing page generation.
Overview
DBaaS (Digital Business as a Service) is a platform that provides access to sophisticated market research and web development. By combining Reddit signal mining, AI-driven pain point analysis, and generative UI, it allows entrepreneurs to validate ideas and launch professional landing pages without writing a single line of code.
- Idea Validation Speed: Minutes
- Workflow Automation: End-to-end
- User Guidance Level: High
Architecture
The platform is built on a modern stack featuring a React 18 + Vite frontend and a microservices backend. Key architectural highlights include global state management via Zustand, resilient API handling with extensive fallback strategies, and a containerized deployment pipeline using Docker.
- Frontend Core: React 18, Vite, Tailwind CSS, and shadcn/ui for a responsive, accessible interface.
- AI Services: Dedicated services for market analysis, Reddit scraping, and landing page synthesis.
- State Management: Zustand stores and React Query for seamless server-state synchronization.
- Infrastructure: Dockerized containers orchestrated for scalability and rapid deployment.
Results
- Accelerated Validation: Reduced time-to-market for new business ideas by 90%.
- High Fidelity: Generated landing pages match the quality of hand-coded professional templates.
- Data-Driven: Decisions are backed by real-time social signals and AI analysis.
DBaaS transformed our idea validation process. We went from a rough concept to a live landing page with real customer signals in under an hour.
— James Miller, Founder, TechStart
Read full case study →
- Category
- Machine Learning & AI
- Tags
- SportsTech, Predictive AI, Injury Prevention, Machine Learning, Python
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Sep 2025
- Read time
- 15 min read
- Live demo
- https://championsgen.framer.website/
Summary: AI-powered player intelligence predicting injuries, forecasting performance, and estimating market value for professional sports teams.
Overview
Champions Gen is a cutting-edge player intelligence platform designed to give professional clubs a competitive edge. By aggregating data from GPS wearables, medical records, and match statistics, it predicts injury risks before they happen and forecasts future player performance. It serves as a central nervous system for decision-making, from the physio room to the transfer market.
- Injury Reduction: 35%
- Valuation Accuracy: 92%
- Data Points/Player: 50k+
- Prediction Window: 6 Months
Architecture
The platform is built on a modular 'AI Core' containing three distinct engines: Injury Prediction, Performance Forecasting, and Market Valuation. Data flows from external sources (GPS APIs, Medical EMRs) through a normalization layer before being processed by these engines. The insights are then served to role-specific dashboards for Medical Staff, Coaches, and Scouts.
- Injury Engine: Multi-factor temporal modeling (Survival Analysis) for risk scoring.
- Performance Engine: Sequence models forecasting player ratings and consistency.
- Valuation Engine: Market regression models estimating fair transfer values.
- Explainability Layer: SHAP-based feature importance to explain 'Why high risk?'.
Features
- Injury Prediction: Forecasts injury probability and severity using historical and real-time load data.
- Performance Forecasting: Projects player form and ratings for upcoming fixtures.
- Market Valuation: Real-time transfer value estimation based on comprehensive performance metrics.
- Medical Dashboards: Specialized heatmaps and alerts for physiotherapy and medical staff.
Results
- Availability: Key player availability increased by 15% season-over-season.
- ROI: Saved an estimated $4M in lost wages and medical costs.
- Scouting: Identified undervalued talent with 20% projected growth upside.
Champions Gen acted like a smoke alarm for our squad. We identified three potential hamstring tears in preseason and adjusted loads, keeping our key players available for the finals.
— Head of Performance, Premier League Club
Read full case study →
- Category
- Agentic AI
- Tags
- AI, RAG, CrewAI, LitServe, Ollama, Privacy
- Author
- Hansika — AI Context Engineer
- Date
- Oct 2025
- Read time
- 10 min read
Summary: A complete AI-powered research and writing assistant using CrewAI and LitServe with a modern glassmorphism web interface, running 100% locally for total privacy.
Overview
Most RAG systems rely on cloud-based LLMs, posing significant privacy risks for sensitive data. This project implements a fully local agentic system where a Researcher agent performs deep web searches and a Writer agent synthesizes the findings, all orchestrated via LitServe and running on local Ollama instances. This ensures that no data ever leaves the user's infrastructure.
- Privacy: 100%
- Setup Time: <5 min
- Local LLM: Qwen2.5/Llama3
- API Performance: Low Latency
Architecture
The system follows a multi-layered architecture starting with a LitServe-powered API gateway. It utilizes CrewAI for agent orchestration, delegating tasks to specialized Researcher and Writer agents. The agents interact with a local Ollama server for inference, providing a seamless and private experience.
- LitServe API: High-performance serving engine for the RAG agents.
- CrewAI Agents: Coordinated Researcher and Writer agents for task completion.
- Ollama Local LLM: Local inference engine ensuring data remains private.
- Flask Web UI: Modern dashboard with glassmorphism for user interaction.
Results
- Data Security: Zero data leaks due to 100% local execution.
- Efficiency: Automated research saves hours of manual searching.
- Accessibility: Easy deployment with Docker and local API endpoints.
The ability to run a research assistant entirely on my own machine without compromising on agent intelligence is a game-changer for our internal documents.
— Marcus Thorne, CTO, SecureData Inc
Read full case study →
- Category
- AI Integration
- Tags
- MCP, Deep Research, Search Agents, Python, Claude Desktop
- Author
- Devulapelly Kushal Kumar — AI Context Engineer
- Date
- Nov 2025
- Read time
- 12 min read
Summary: A powerful Model Context Protocol (MCP) server that empowers LLMs to perform recursive, deep-dive internet research tasks autonomously.
Overview
Current LLMs struggle with deep research. They hallucinate, stop after one search, or lack current data. ResearchFlow is an MCP server that bridges this gap. It provides a structured 'Deep Research' tool that enables Claude or Cursor to recursively search, analyze multiple sources, verify facts, and synthesize comprehensive reports in a single session.
- Search Depth: Recursive
- Fact Accuracy: 95%+
- Setup Time: < 2 Mins
- Sources: Web/Academic
Architecture
The ResearchFlow architecture places the MCP Server as the central conductor. When a user asks a complex question, the server orchestrates a multi-step plan. It calls external APIs (like Exa for neural search, Arxiv for papers) and feeds the results back to the LLM for synthesis, repeating the loop until the confidence threshold is met.
- MCP Server: Python-based server implementing the Model Context Protocol.
- Search Tools: Integrated connectors for Exa.ai, Google Search, and Wikipedia.
- Planner Agent: Decomposes vague queries into actionable search steps.
- Verifier: Cross-checks facts against multiple sources before final output.
Features
- Recursive Search: Automatically follows leads and refines queries based on initial findings.
- Auto-Citation: Embeds source links directly into the final generated text.
- Academic Mode: Filters search results to strictly peer-reviewed papers and journals.
- Export to Markdown: One-click export of the research report to a formatted Markdown file.
Results
- Speed: Accelerates information gathering by 20x.
- Coverage: Aggregates data from 50+ sources per report.
- Citation: Every claim is backed by a direct URL reference.
ResearchFlow turns a 2-hour literature review into a 5-minute background task. It finds papers I would have definitely missed.
— Dr. Alisha Gupta, Research Scientist
Read full case study →
- Category
- Data Engineering
- Tags
- Scraping, Apify, Python, Data Mining, Job Automated
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Oct 2025
- Read time
- 12 min read
Summary: A production-ready guide on building resilient LinkedIn job scrapers using Apify Actors and Python, designed to bypass auth-walls and rate limits.
Overview
Scraping LinkedIn is notoriously difficult due to strict anti-bot measures. This case study details how we utilized Apify's infrastructure to deploy a robust scraper that rotates residential proxies and manages browser fingerprints. The system extracts job titles, descriptions, and salary ranges, cleaning the data into a standardized JSON format for analysis.
- Success Rate: 98%
- Jobs/Hour: 10,000+
- Proxy Cost: Optimized
- Format: JSON/CSV
Architecture
The architecture leverages Apify Actors to handle the heavy lifting of browser orchestration. A central 'Manager' script queues job URLs, while worker actors scrape data in parallel using stealth-mode Playwright. Data is pushed to an Apify Dataset and eventually synced to a PostgreSQL warehouse.
- Apify Actor: Serverless container running the scraping logic.
- Residential Proxies: Rotated IPs to mimic human traffic from specific geolocations.
- Request Queue: Manages URL frontier and retries failed requests.
- Data Transformer: Python script that normalizes raw HTML into structured entities.
Features
- Stealth Mode: Bypasses bot detection using advanced browser fingerprinting techniques.
- Geotargeting: Scrape jobs as if you were physically located in any country.
- Schema Validation: Ensures no incomplete records enter the database.
- Rate Limiting: Intelligent throttling to emulate human browsing speeds.
Results
- Scale: Unlimited horizontal scaling via serverless actors.
- Reliability: Automatic retries handle transient network failures.
- Freshness: Real-time market insights with hourly runs.
Using Apify allowed us to scale from 100 jobs a day to 100,000 without worrying about server maintenance or IP bans.
— Lead Recruiter, Talent Agency
Read full case study →
- Category
- Backend Engineering
- Tags
- Python, Pydantic, FastAPI, Validation, Type Safety
- Author
- Hansika — AI Context Engineer
- Date
- Sep 2025
- Read time
- 10 min read
Summary: How to use Pydantic to enforce strict data schemas in Python applications, ensuring that 'garbage in' never leads to 'garbage out'.
Overview
In dynamic languages like Python, data bugs are common. Pydantic solves this by parsing and validating data against pre-defined classes. We use it everywhere in our stack—from validating API requests in FastAPI to cleaning LLM outputs. This case study demonstrates advanced usage patterns like custom validators, nested models, and settings management.
- Bugs Prevented: Hundreds
- Performance: Rust Core
- Dev Exp: Excellent
- Adoption: 100%
Architecture
Pydantic sits at the boundary of your application. Whether it's an incoming HTTP request, a database query result, or a configuration file, Pydantic intercepts the raw data, validates it against a schema, and converts it into a typed Python object. If validation fails, it raises a precise error detailing exactly what went wrong.
- BaseModel: The core class defining the data schema.
- Validator: Custom logic to enforce complex constraints (e.g., 'age must be > 18').
- Serialization: Converting typed models back to JSON/Dicts safely.
- Settings Config: Managing environment variables with type safety.
Features
- Runtime Enforcement: Ensures data matches spec at the moment of execution.
- JSON Schema Export: Auto-generates OpenAPI docs from Python code.
- Recursive Models: Supports complex nested data structures easily.
- Data Parsing: Coerces compatible types (e.g., string '1' to int 1) intelligently.
Results
- Security: Prevents malformed data injections.
- Clarity: Code is self-documenting via type hints.
- Speed: Pydantic V2 (Rust) provides massive serialization speedups.
Pydantic is the single most important library in our Python stack. It catches 90% of bugs before code even runs.
— Senior Architect, Apex Neural
Read full case study →
- Category
- FinTech
- Tags
- Stripe, Payments, API, Security, Webhooks
- Author
- Rahul Patil — AI Context Engineer
- Date
- Nov 2025
- Read time
- 15 min read
Summary: A critical look at building robust payment flows using Stripe. Handling race conditions, ensuring idempotency, and securing webhook endpoints.
Overview
Integrating a payment gateway like Stripe looks easy on the surface, but edge cases abound. Network timeouts, double-clicks, and delayed webhooks can lead to double charges or missed access provisioning. This guide details our 'Idempotent Transaction Pattern' which guarantees that every payment action happens exactly once, regardless of network failures.
- Uptime: 99.99%
- Errors: Zero
- Integrity: ACID
- Security: TLS 1.3
Architecture
The payment flow involves three parties: Content (User), Server (API), and Gateway (Stripe). Our server creates a PaymentIntent and passes a client_secret to the frontend. Crucially, we use Idempotency Keys for all write operations to Stripe. Fulfillment happens asynchronously via Webhooks, verified by cryptographic signatures to prevent spoofing.
- Payment Intent: Stateful object tracking the lifecycle of a charge.
- Idempotency Layer: Middleware ensuring retried requests don't duplicate side effects.
- Webhook Handler: Async processor for events like 'payment_intent.succeeded'.
- Reconciliation Job: Nightly script ensuring DB matches Stripe ledger.
Features
- Webhook Verification: Cryptographically verifies that events actually came from Stripe.
- Idempotency: Prevents duplicate operations during network failures.
- Metadata Tracking: Attaches internal IDs (User ID, Order ID) to Stripe objects for tracking.
- Robust Logging: Tracks every state change in the payment lifecycle.
Results
- Trust: Users feel secure knowing billing is accurate.
- Compliance: Fully audit-ready transaction logs.
- Resilience: Immune to frontend connectivity drops.
Implementing strict webhooks and idempotency saved us from hundreds of support tickets regarding duplicate charge disputes.
— CFO, SaaS Startup
Read full case study →
- Category
- AI Integration
- Tags
- MCP, Claude, Local AI, Tooling, Integration
- Author
- Ramya — Senior Engineer - Integrations and Applied AI
- Date
- Oct 2025
- Read time
- 14 min read
Summary: A comprehensive guide on configuring the Model Context Protocol (MCP) to give Claude Desktop access to your local file system, databases, and custom scripts.
Overview
The Model Context Protocol (MCP) is a standardized way for AI assistants to talk to external systems. This guide explains how to set up `claude_desktop_config.json` to enable local servers—like a SQLite inspector or a File System agent. By the end, you will have a Claude instance that can read your logs, query your dev database, and edit code files directly.
- Complexity: Medium
- Power: Unlimited
- Setup: JSON Config
- Protocol: Open Std
Architecture
MCP operates on a Client-Host-Server model. 'Claude Desktop' acts as the Host. You run local 'Servers' (e.g., Python scripts). The Host connects to these Servers via Stdio (Standard Input/Output). When you ask a question, Claude sees the tools offered by the Server and can choose to execute them, receiving the output back into the chat context.
- Host (Claude): The UI where the user interacts.
- MCP Client: The internal engine managing connections.
- MCP Server: An executable (e.g., `uvx mcp-server-filesystem`) exposing tools.
- Transport: Stdio or SSE (Server-Sent Events) for communication.
Features
- Universal Standard: Write a tool once, use it in Claude, Zed, or any MCP client.
- Local Execution: Data stays on your machine; only tool outputs go to the model.
- Hot-Swappable: Enable/Disable servers via config without reinstalling.
- Resource Mapping: Expose static files or dynamic data streams as first-class context.
Results
- Efficiency: No more copy-pasting code context.
- Agency: AI takes actions, not just gives text.
- Extensibility: Write your own tools in Python/TS easily.
MCP transforms Claude from a chat bot into a pair programmer that actually knows my codebase.
— Senior Dev, Open Source Contributor
Read full case study →
- Category
- Prompt Engineering
- Tags
- Generative Art, Midjourney, JSON Mode, Style Transfer, Structured Output
- Author
- Vedant Pai — AI Context Engineer
- Date
- Sep 2025
- Read time
- 11 min read
Summary: Mastering the art of style-specific image generation ('Toon') and strict structured text generation ('JSON') to build reliable creative applications.
Overview
Prompt engineering splits into two disciplines: Creative (Style) and Structural (Format). This case study covers both. Part 1 explores 'Toon' prompting—creating consistent 3D Pixar/Disney style characters. Part 2 explores 'JSON Mode'—forcing LLMs to output machine-readable code for API integration. Together, they form the basis of modern AI apps.
- Consistency: High
- Parse Rate: 100%
- Style: 3D/2D
- Platform: MJ/GPT
Architecture
For Image Generation, we use a 'Style Token' approach, pre-defining a lexicon of lighting and render terms (e.g., 'Octane Render', 'Subsurface Scattering'). For Text, we utilize the model's native 'JSON Mode' combined with Zod/Pydantic schema definitions in the system prompt to guarantee valid syntax.
- Style Prompt: Injecting aesthetic keywords (e.g., 'Pixar style', 'claymation').
- Negative Prompt: Removing unwanted artifacts (e.g., 'low res', 'blurry').
- System Instruction: Enforcing 'You are a JSON generator' behavior.
- Schema Def: Providing the exact JSON structure expected in the output.
Features
- JSON Mode Enforcement: Guarantees output is parseable by `JSON.parse()`.
- Style Macros: Reusable prompt fragments for consistent art direction.
- Seed Control: Using random seeds to reproduce specific image outputs.
- Parameter Tuning: Adjusting `temperature` for text and `--stylize` for images.
Results
- Reliability: No more markdown or conversational filler in API responses.
- Aesthetics: Consistent 'Toon' look across hundreds of generated assets.
- Integration: Seamlessly fits into Javascript/Python logic.
Rigid JSON controls combined with creative style prompts allowed us to build an automated children's book generator that actually looks good.
— Indie Hacker, App Developer
Read full case study →
- Category
- Cloud Infrastructure
- Tags
- GPU Cloud, Serverless, Docker, LLM Serving, Infrastructure
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Nov 2025
- Read time
- 13 min read
Summary: How RunPod is democratizing AI compute by offering serverless GPU containers. A deep dive into auto-scaling LLM inference endpoints without managing Kubernetes clusters.
Overview
Traditional cloud providers (AWS, GCP) are expensive and complex for transient AI workloads. RunPod changes the game by offering 'Serverless Pods'—Docker containers that wake up only when a request comes in. We migrated our entire text-to-image pipeline to RunPod, reducing idle costs by 80% while maintaining sub-second cold starts.
- Cost Savings: 80%
- Cold Start: <2s
- GPUs: H100/A6000
- Scale: Auto-zero
Architecture
The architecture consists of a custom Docker image containing the model weights (baked in for speed). This image is deployed to RunPod's Serverless platform. A global load balancer routes API requests to available pods. If no pods are active, RunPod provisions one instantly from a 'warm pool'. Network Volumes provide persistent storage for LoRA adapters across pod restarts.
- Custom Handler: Python entrypoint function that loads the model.
- Network Volume: Shared high-speed storage for large model files.
- Auto-Scaler: Logic that spins up 0-100 GPUs based on queue depth.
- Registry: Container registry hosting the optimized inference image.
Features
- Global Mesh: Deploy pods across multiple regions for low latency.
- Secure Enclaves: Confidential compute options for sensitive data.
- Template Gallery: One-click deploy for Stable Diffusion, LLAMAs, and more.
- Websocket Support: Streaming tokens support for fast LLM chat experiences.
Results
- Elasticity: Perfect handling of 'Hacker News' traffic spikes.
- Economics: Pay-per-second billing means zero waste.
- Performance: Access to bleeding-edge H100s without contracts.
RunPod allowed us to launch a viral AI app overnight. We went from 10 to 10,000 users without changing a single line of infrastructure code.
— Startup Founder, AI Application
Read full case study →
- Category
- Generative Art
- Tags
- ComfyUI, Stable Diffusion, Nodes, Workflows, SDXL
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Oct 2025
- Read time
- 15 min read
Summary: Moving beyond basic web UIs to 'Node-Based' generative pipelines. How ComfyUI enables granular control over every step of the diffusion process.
Overview
Standard interfaces like Automatic1111 mask the complexity of diffusion models. ComfyUI exposes the internal wiring. By treating the latent space, VAE, CLIP, and Sampler as separate 'nodes', we can build complex workflows—like 'Hires Fix', 'Inpainting', and 'ControlNet Stacking'—that simple UIs cannot handle. It is the professional's choice for reproducibility.
- Efficiency: 2x Faster
- Memory: Low VRAM
- Flexibility: Infinite
- Format: .json Flow
Architecture
ComfyUI operates on a graph execution model. Data flows from left to right: Checkpoint Loader -> CLIP Text Encode -> KSampler -> VAE Decode -> Save Image. Because it caches intermediate results (like model loading), tweaking a prompt at the end of a chain doesn't require reloading the 6GB checkpoint, making iteration incredibly fast.
- Checkpoint Loader: Loads the Safetensors model into VRAM.
- KSampler: The core engine performing the denoising steps.
- ControlNet Stack: Injecting structural guidance (pose, edges) into generation.
- Latent Upscaler: Upscaling images in latent space for sharpness.
Features
- Visual Debugging: See exactly what the model 'sees' at each step via preview nodes.
- Custom Nodes: Extend functionality with Python scripts (e.g., JoyTag, IP-Adapter).
- Batch Processing: Queue hundreds of variations with simple list inputs.
- Area Composition: Define different prompts for specific regions of the canvas.
Results
- Speed: Optimized VRAM usage allows generation on lower-end GPUs.
- Reproducibility: Exact node settings ensure consistent output.
- Modular: Easily swap out components (e.g., change VAE) without breaking flow.
ComfyUI saved our production pipeline. The ability to save a graph as a JSON file meant we could version control our image generation logic.
— Studio Lead, Game Studio
Read full case study →
- Category
- Generative Art
- Tags
- FaceID, LoRA, ControlNet, Storytelling, Comics
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Sep 2025
- Read time
- 12 min read
Summary: The holy grail of AI storytelling: Keeping a character's face and clothing identical across different scenes, angles, and lighting conditions.
Overview
The biggest hurdle for AI comics and movies is that valid AI models behave like a chaotic dream—every generation yields a slightly different person. To solve this, we employ a 'Consistency Stack': combining IP-Adapter (for general features), FaceID (for identity), and LoRA (for specific clothing). This ensures our protagonist 'Alex' looks like 'Alex' whether he's at a cafe or on Mars.
- Similarity: 95%+
- Angles: 360 Deg
- Outfit: Locked
- Control: Full
Architecture
Consistency isn't achieved by one tool, but a layering of constraints. We start with a high-quality 'Reference Sheet' of the character. During generation, we use 'IP-Adapter FaceID Plus' to inject the facial embeddings directly into the model's attention layers, bypassing the text prompt's ambiguity. We essentially 'force' the model to draw the reference face.
- Reference Sheet: Grid image showing front, side, and 3/4 views.
- IP-Adapter FaceID: Model that transfers facial features from image to image.
- OpenPose: ControlNet model to dictate the character's body position.
- Inpainting: Fixing small details (eyes, hands) in post-prod.
Features
- FaceID Integration: Uses face recognition embeddings for max likeness.
- Attention Masking: Apply consistency only to the face, allowing outfit changes.
- Multi-Character: Render two consistent characters interacting in one scene.
- Style Transfer: Keep the character consistent even when changing art styles (e.g., Pixel Art).
Results
- Brand Identity: Mascots remain recognizable across campaigns.
- Speed: No need for finetuning a LoRA for every minor character.
- Quality: Retains skin texture and micro-details of the reference.
Before this stack, we had to photoshop every frame. Now, the AI gets the face right 9 times out of 10.
— Comic Artist, Indie Publisher
Read full case study →
- Category
- Generative AI
- Tags
- IP-Adapter, Style Transfer, ControlNet, Canny, Reference
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Nov 2025
- Read time
- 11 min read
Summary: Understanding the 'Image Prompt Adapter', a lightweight module that allows diffusion models to 'see' reference images. The secret weapon for style cloning and composition.
Overview
Text prompts are often insufficient to describe complex visual styles or specific objects. IP-Adapter (Image Prompt Adapter) solves this by decoupling the cross-attention mechanism. It allows you to feed an image (e.g., a specific wooden chair, or a specific Van Gogh painting) into the model as a prompt. The model then generates new content that mimics the *content* or *style* of that reference with uncanny accuracy.
- Precision: Pixel-Level
- Weight: 22MB
- Versatility: Style/Object
- Compat: SD1.5/SDXL
Architecture
Unlike LoRAs which require fine-tuning, IP-Adapter is a plug-and-play module. It uses a separate image encoder (CLIP Vision) to extract feature embeddings from the reference image. These embeddings are then projected into the UNet's cross-attention layers, effectively 'hijacking' the text prompt pathway to pay attention to visual features instead.
- Image Encoder: Converts pixels to semantic vector embeddings.
- Projector: Maps image embeddings to the same dimension as text embeddings.
- Decoupled Cross-Attn: Layers that attend to image features separately from text.
- Weight Slider: Controls how much influence the reference image has (0.0 - 1.0).
Features
- IP-Adapter Plus: A stronger variant that captures fine-grained details.
- FaceID: Specialized variant for facial identity retention.
- Attention Masking: Apply style only to specific regions (e.g., only the shirt).
- Lightweight: No heavy model weights to download; runs alongside Checkpoints.
Results
- Zero-Shot: Works on any style without training.
- Coherence: Maintains object integrity better than text.
- UX: Enables 'visual prompting' interfaces.
IP-Adapter kills the need for 'prompt engineering'. I just show the model what I want, and it understands instantly.
— Art Director, Design Agency
Read full case study →
- Category
- Agentic AI
- Tags
- Parlant, LLM, Conversational AI, Agent Design, Python, AI Architecture
- Author
- Ramya — Senior Engineer - Integrations and Applied AI
- Date
- Oct 2025
- Read time
- 16 min read
Summary: A comprehensive comparison demonstrating the superiority of Parlant's structured guideline-based approach over traditional monolithic LLM prompts for building reliable, maintainable conversational AI agents.
Overview
Traditional LLM prompts suffer from a fundamental flaw: they pack all instructions, rules, edge cases, and domain knowledge into a single massive prompt, creating an unmaintainable, unreliable system where critical rules can be ignored. This project demonstrates a paradigm shift using Parlant's structured approach with conditional guidelines and dynamic tools, proving that modular agent design dramatically improves reliability, observability, and maintainability for production conversational AI systems.
- Prompt Complexity Reduction: 95%
- Rule Enforcement Guarantee: 100%
- Maintainability Score: 10x
- Token Usage Reduction: 70%
Architecture
The system implements two parallel architectures for direct comparison. The Traditional LLM uses a single monolithic 223-line prompt sent to OpenAI's GPT-4, while the Parlant Agent uses a structured server with conditional guidelines and tool orchestration. Both handle identical queries to demonstrate the stark differences in reliability and maintainability.
- Traditional Pipeline: Single massive prompt → OpenAI GPT-4 → Unstructured response
- Parlant Agent Server: Manages conditional guidelines, tool orchestration, and agent state
- Guideline Engine: Evaluates conditions and triggers relevant guidelines with tool calls
- Tool Registry: 8 specialized tools for calculations, data retrieval, and structured responses
- Flask API Server: Serves web frontend and proxies requests to both traditional and Parlant approaches
- Interactive Frontend: Side-by-side comparison UI showing responses, reasoning traces, and performance metrics
Features
- Modular Guideline Architecture: 9 focused conditional guidelines replace a 223-line monolithic prompt, each triggering only when needed with guaranteed execution.
- Dynamic Tool Integration: 8 specialized tools enable real-time calculations, data retrieval, and structured responses instead of relying on static prompt text.
- Guaranteed Critical Rule Enforcement: Unlike traditional prompts where LLMs might ignore instructions, Parlant ensures critical guidelines always trigger and execute.
- Full Observability & Reasoning Traces: Every response shows which guidelines matched and which tools were called, enabling debugging and quality assurance impossible with traditional approaches.
- Side-by-Side Comparison Interface: Interactive web frontend and CLI demo allow real-time comparison of both approaches on identical queries, clearly demonstrating the advantages.
Results
- Reliability: 100% enforcement of critical rules vs 60-70% with traditional prompts
- Maintainability: Isolated guideline updates vs risky monolithic prompt edits
- Observability: Full reasoning traces vs black-box responses
- Cost Efficiency: 70% reduction in tokens per request
This comparison opened our eyes. We were struggling with a 300-line prompt that was impossible to maintain. Switching to Parlant's guideline approach not only reduced our codebase by 90% but also eliminated the critical edge cases our old prompt kept missing. It's not even close - structured guidelines are the only way to build production conversational AI.
— Michael Chen, Director of AI Engineering, FinTech Solutions Inc
Read full case study →
- Category
- Agentic AI
- Tags
- Multi-Agent AI, RAG, CrewAI, Context Engineering, Python, Vector Search
- Author
- Ramya — Senior Engineer - Integrations and Applied AI
- Date
- Dec 2025
- Read time
- 20 min read
- Live demo
- https://contextstack.apexneural.cloud
Summary: An intelligent multi-agent research assistant that combines RAG, web search, memory systems, and API integrations using CrewAI Flows to deliver contextually rich, well-cited responses to complex research queries.
Overview
Research tasks today require synthesizing information from multiple sources - historical documents, real-time web data, conversation context, and external APIs. Traditional single-source systems fall short. This project delivers an intelligent research assistant that orchestrates specialized AI agents to gather, evaluate, and synthesize information from diverse sources, providing researchers with coherent, well-cited answers backed by comprehensive context evaluation.
- Context Relevance: 99.2%
- Response Time: <8s
- Source Integration: 4 Types
- Citation Accuracy: 98.5%
Architecture
The system employs a Hub-and-Spoke multi-agent architecture powered by CrewAI Flows. A central ResearchAssistantFlow orchestrates parallel execution of specialized agents (RAG, Memory, Web Search, Tool Calling), aggregates their outputs, and routes them through sequential processing via Evaluator and Synthesizer agents for intelligent filtering and coherent response generation.
- ResearchAssistantFlow: Central orchestrator managing agent coordination and workflow execution
- RAG Agent: Searches through parsed research documents using TensorLake + Voyage + Qdrant
- Memory Agent: Retrieves conversation history and user preferences from Zep Cloud
- Web Search Agent: Fetches real-time information via Firecrawl web search
- Tool Calling Agent: Interfaces with external APIs (ArXiv, etc.) for extended capabilities
- Evaluator Agent: Filters context relevance using confidence scoring and reasoning
- Synthesizer Agent: Generates coherent responses with proper citations and structured output
Features
- Multi-Agent Flow Architecture: Six specialized agents work in parallel and sequence: RAG Agent for document search, Memory Agent for conversation history, Web Search Agent for real-time information, Tool Agent for external APIs, Evaluator Agent for relevance filtering, and Synthesizer Agent for coherent response generation.
- Advanced RAG Pipeline: TensorLake for complex document parsing with structured extraction, Voyage Context 3 embeddings for contextualized semantic understanding, and Qdrant vector database for high-performance similarity search across research documents.
- Intelligent Context Evaluation: Evaluator agent automatically filters irrelevant information using confidence-based scoring, ensuring only the most relevant context from each source is used for final synthesis.
- Persistent Memory with Zep Cloud: Graph-based agentic memory maintains conversation history, user preferences, and context summaries across sessions, enabling personalized and contextually aware responses.
- Comprehensive Citation System: Every response includes source attribution with relevance scores (0-1), reasoning explanations, and detailed citation metadata including page numbers, chunk indices, and confidence levels.
- Production-Ready Observability: Integrated Langfuse tracking provides comprehensive observability for all LLM calls, including traces, spans, generations, token usage, and cost analysis for monitoring and optimization.
Results
- Efficiency: Reduced research time from hours to minutes with parallel context gathering
- Accuracy: 99.2% context relevance with intelligent evaluation and filtering
- Trust: Complete source transparency with detailed citations and confidence scores
- Scale: Handles thousands of documents with sub-8-second response times
This research assistant transformed our workflow. What used to take hours of cross-referencing papers and documents now happens in seconds with complete citations. The multi-agent approach ensures we never miss relevant context.
— Dr. Michael Chen, Research Lead, AI Research Institute
Read full case study →
- Category
- Agentic AI
- Tags
- MCP, CrewAI, Web Scraping, Agentic AI, Bright Data, Deep Research, Streamlit
- Author
- Rahul Patil — AI Context Engineer
- Date
- Nov 2025
- Read time
- 18 min read
- Live demo
- https://multiplatform.apexneural.cloud/
Summary: A multi-agent, MCP-powered research system that performs deep, parallel analysis across social platforms and the open web.
Overview
Modern research workflows require extracting, validating, and synthesizing information across multiple platforms such as social media, video platforms, and the open web. Manual research is slow, inconsistent, and does not scale. The Multiplatform Deep Researcher was built to address this challenge using an MCP-powered, multi-agent architecture capable of parallel, platform-specific deep research.
- Platforms Supported: 5+
- Research Parallelism: Asynchronous
- Data Sources: Web + Social Media
- Human Effort Reduced: 80%+
Architecture
The system follows a multi-agent, MCP-centric architecture. CrewAI orchestrates specialized research agents, each responsible for a specific platform. Agents interact with Bright Data's Web MCP server through the Model Context Protocol, enabling reliable and standardized access to web-scale data.
- Streamlit UI: Provides an interactive interface for defining research queries and viewing aggregated results.
- CrewAI Orchestrator: Manages agent lifecycles, task delegation, and parallel execution.
- Platform-Specific Research Agents: Dedicated agents for Instagram, LinkedIn, YouTube, X (Twitter), and the open web.
- MCP Client Layer: Implements the Model Context Protocol to communicate with external data tools.
- Bright Data Web MCP Server: Handles web scraping, proxy rotation, and platform-specific access logic.
Features
- Multi-Agent Orchestration: Five specialized agents work in parallel: Instagram, LinkedIn, YouTube, X (Twitter), and Web Research agents, each optimized for their platform.
- MCP Integration: Model Context Protocol provides standardized interface between agents and web tools, improving security and maintainability.
- Bright Data Integration: Enterprise-grade web scraping with automatic proxy rotation, CAPTCHA solving, and platform-specific access logic.
- Parallel Execution: Asynchronous agent execution allows simultaneous platform research, dramatically reducing latency.
- Graceful Degradation: Per-agent timeout handling and partial result aggregation ensure system reliability even if individual platforms fail.
- Interactive UI: Streamlit-based interface provides clean, accessible research experience for non-technical users.
Results
- Research Depth: Significantly deeper insights compared to single-source research
- Speed: Parallel execution reduced research time by 80%+
- Scalability: New platforms added by introducing new agents without architectural changes
- Reliability: MCP abstraction reduced scraping failures and maintenance overhead
The Multiplatform Deep Researcher transformed how we conduct competitive intelligence. What used to take our team days of manual research across platforms now completes in minutes with deeper insights and better citations.
— Sarah Mitchell, Head of Market Intelligence, TechCorp
Read full case study →
- Category
- DevOps & MLOps
- Tags
- CI/CD, DevOps, Docker, AWS, GitLab, Multi-Agent AI, Infrastructure Automation, Zero-Downtime Deployment
- Author
- Ayush — AI Systems Architect
- Date
- Nov 2024
- Read time
- 16 min read
Summary: How we architected and implemented a production-grade CI/CD pipeline supporting development, staging, and production environments for our agentic AI platform, enabling automated testing, Docker containerization, infrastructure provisioning, and zero-downtime deployments with complete environment isolation.
Overview
Our enterprise AI platform powered by multiple agentic AI systems required a sophisticated deployment strategy to support rapid iteration while maintaining production stability. The platform serves Fortune 500 clients with strict SLA requirements (99.9% uptime), processes 50K+ AI agent requests daily, and required frequent updates to both ML models and application logic. Manual deployments were taking 2+ hours, prone to human error, and lacked proper testing in staging environments. We designed and implemented a comprehensive multi-environment CI/CD pipeline using GitLab CI/CD, Docker, AWS services (EC2, RDS, S3, Lambda), and Infrastructure as Code (Terraform). The pipeline provides automated testing (unit, integration, E2E), security scanning, Docker containerization, environment-specific configuration management, automated database migrations, blue-green deployments for zero-downtime, and instant rollback capabilities.
- Deployment Time Reduction: 93%
- Environments Managed: 3
- Daily Deployments: 15+
- Uptime Achieved: 99.9%
Architecture
The CI/CD pipeline follows a branch-based workflow integrated with GitLab CI/CD. Code commits trigger automated builds that run tests, security scans, and quality checks. The pipeline consists of five stages: Build (Docker image creation with multi-stage builds), Test (unit, integration, E2E, security scanning), Deploy-Dev (automatic deployment to development environment), Deploy-Staging (manual approval required, full testing suite), and Deploy-Production (manual approval with blue-green strategy). Each environment is completely isolated with separate AWS accounts, VPCs, databases, and S3 buckets. Infrastructure is managed through Terraform with separate state files per environment.
- GitLab CI/CD: Pipeline orchestration with branch-based workflows, manual approval gates, and deployment tracking
- Docker Multi-Stage Builds: Optimized containerization with separate dev and production configurations, reducing image size by 60%
- AWS ECR: Container registry with automated vulnerability scanning, image versioning, and lifecycle policies
- Terraform Modules: Infrastructure as Code for EC2, RDS, S3, VPC, security groups, and load balancers with state management
- AWS Application Load Balancer: Traffic routing for blue-green deployments with health checks and gradual traffic shifting
- CloudWatch & X-Ray: Comprehensive monitoring, logging, distributed tracing, and alerting for deployment health tracking
Results
- Deployment Velocity: 15+ daily deployments vs 2 weekly deployments previously
- Time to Production: 8 minutes vs 2 hours for complete deployment cycle
- System Uptime: 99.9% uptime achieved with zero-downtime blue-green deployments
- Incident Reduction: 80% fewer deployment-related production incidents
- Team Productivity: Developers spend 70% less time on deployment tasks
The CI/CD pipeline completely changed how we ship features. We went from dreading deployments to deploying multiple times a day with complete confidence. The automated testing and zero-downtime deployments mean we can innovate fast without breaking production.
— VP of Engineering, Enterprise AI Platform
Read full case study →
- Category
- Cloud Infrastructure & DevOps
- Tags
- AWS, Docker, Auto Scaling, Multi-Tenant, Redis, PostgreSQL, GitLab CI/CD, Infrastructure Automation, Monitoring
- Author
- Ayush — AI Systems Architect
- Date
- Oct 2024
- Read time
- 20 min read
Summary: How we architected and automated cloud infrastructure for a multi-tenant SaaS platform serving 10K+ users across 500+ organizations, implementing automated scaling, deployment orchestration, comprehensive monitoring, and tenant isolation while reducing infrastructure costs by 40% through intelligent resource optimization.
Overview
Our multi-tenant SaaS platform providing HRM, CRM, and custom enterprise solutions required infrastructure that could scale dynamically while maintaining strict tenant isolation, cost efficiency, and operational reliability. The platform serves 10K+ users across 500+ organizations with varying usage patterns. Initial infrastructure was manually provisioned, couldn't handle traffic spikes (leading to 3-4 outages monthly), and infrastructure costs were 60% higher than industry benchmarks. We designed and implemented a comprehensive infrastructure automation solution using AWS services (EC2 Auto Scaling Groups, RDS with Multi-AZ, ElastiCache Redis Cluster, S3 with lifecycle policies, CloudFront CDN), Docker containerization, Terraform for Infrastructure as Code, GitLab CI/CD for deployment automation, and comprehensive monitoring using CloudWatch, Prometheus, and Grafana.
- Users Supported: 10K+
- Organizations: 500+
- Cost Reduction: 40%
- Uptime Achieved: 99.95%
Architecture
The infrastructure follows a three-tier architecture with high availability across multiple AWS Availability Zones. The presentation tier consists of CloudFront CDN for static assets and Application Load Balancer for dynamic content distribution. The application tier runs FastAPI/Django applications in Docker containers on EC2 instances managed by Auto Scaling Groups. The data tier includes RDS PostgreSQL Multi-AZ for transactional data, ElastiCache Redis Cluster for caching and sessions, and S3 for file storage. All tiers are deployed in a private VPC with public subnets for load balancers and private subnets for application and database servers. Security groups implement defense-in-depth with principle of least privilege.
- CloudFront CDN: Global content delivery network caching static assets with 95% cache hit rate reducing origin load
- Application Load Balancer: Multi-AZ load balancing with SSL termination, health checks, and request routing based on path patterns
- EC2 Auto Scaling Groups: Separate ASGs for web servers and workers with predictive scaling and automatic instance replacement
- RDS PostgreSQL Multi-AZ: High-availability database with automatic failover, read replicas, and automated backup/recovery
- ElastiCache Redis Cluster: Multi-node Redis cluster with automatic sharding, replication, and failover for caching and sessions
- S3 with Lifecycle Policies: Object storage with intelligent tiering, versioning, and automated archival to Glacier for cost optimization
Results
- Zero Outages: From 3-4 monthly outages to zero outages in 6 months
- Cost Reduction: 40% reduction in infrastructure costs through intelligent scaling and reserved instances
- Scale Performance: Scales from 50 to 500+ concurrent users automatically in under 3 minutes
- Database Performance: 70% reduction in database load through intelligent caching strategies
- Recovery Time: RTO of 15 minutes and RPO of 5 minutes for disaster recovery
Our infrastructure now handles 10x traffic spikes without any manual intervention. We haven't had a single outage in 6 months, and our AWS bill is 40% lower than before despite supporting 3x more users.
— CTO, Multi-Tenant SaaS Platform
Read full case study →
- Category
- Python SDK
- Tags
- Python, SaaS, Authentication, PayPal, SendGrid, JWT, SDK, Database-Agnostic, Framework-Agnostic
- Author
- Praveen Jogi — AI Context Engineer
- Date
- Dec 2024
- Read time
- 12 min read
Summary: A comprehensive Python SDK that unifies authentication, payments, and email services into a single, database-agnostic, framework-agnostic solution for modern SaaS applications.
Overview
Building a SaaS application requires implementing three critical components: user authentication, payment processing, and email notifications. Each of these typically requires weeks of development, integration with third-party services, and extensive testing. ApexSaaS solves this by providing a unified, production-ready Python SDK that handles all three components with a clean, intuitive API. The package is completely database-agnostic and framework-agnostic, allowing developers to integrate it into any Python application—whether using FastAPI, Flask, Django, or custom frameworks—without being locked into a specific architecture.
- Development Time Saved: 60%
- Core Modules: 3
- Python Version: 3.8+
- Dependencies: 6
Architecture
ApexSaaS follows a modular architecture with three independent core modules (Auth, Payments, Email) that share common infrastructure. The Auth module handles user authentication and JWT token management. The Payments module integrates with PayPal's REST API for payment processing. The Email module uses SendGrid's API for transactional emails. All modules share core utilities for security (password hashing, JWT), configuration management, and error handling, while remaining completely decoupled from any database or framework.
- Auth Module: Handles user signup, login, logout, password reset, email verification, and JWT token creation/validation with bcrypt password hashing
- Payments Module: Integrates with PayPal API for creating orders, capturing payments, managing subscription plans, processing refunds
- Email Module: SendGrid integration for sending verification emails, password reset emails, welcome emails, payment confirmations
- Core Infrastructure: Shared utilities for JWT token management, password hashing (bcrypt), configuration management, error handling
- Exception System: Custom exception classes (ApexError, ApexAuthError, ApexPaymentError, ApexEmailError) for proper error handling
Results
- Development Speed: Reduced time-to-market by 60% with pre-built authentication, payments, and email modules
- Framework Flexibility: Works seamlessly with FastAPI, Flask, Django, and any Python framework
- Production Ready: Battle-tested code with comprehensive error handling and security best practices
- Integration Time: From installation to working authentication, payments, and emails in under 30 minutes
ApexSaaS reduced our development time by 60%. We went from building authentication, payments, and email from scratch to having a production-ready solution in under a day. The database-agnostic design meant we could use it with our existing PostgreSQL setup without any modifications.
— Development Team, SaaS Startup
Read full case study →
- Category
- AI Observability
- Tags
- Langfuse, LLM Observability, Cost Tracking, Prompt Management, AI Monitoring, Python
- Author
- Praveen Jogi — AI Context Engineer
- Date
- Dec 2024
- Read time
- 18 min read
Summary: How we integrated Langfuse observability into our DBaaS multi-agent AI platform to achieve complete transparency into LLM operations, enabling real-time cost tracking, prompt versioning, and performance monitoring across PainPointExtractorAgent, MarketGapGeneratorAgent, and MarketIdeaExpanderAgent.
Overview
Our DBaaS platform operates three specialized AI agents (PainPointExtractorAgent, MarketGapGeneratorAgent, MarketIdeaExpanderAgent) that process thousands of market research requests daily. As the platform scaled, we faced critical challenges: no visibility into LLM operation costs, inability to track token usage, difficulty debugging agent failures, and no way to version or A/B test prompts without code deployments. We integrated Langfuse as our observability solution to solve these challenges. This case study details how we implemented a comprehensive Langfuse integration layer that provides real-time cost tracking, token usage monitoring, prompt versioning, user/session analytics, and automated quality scoring across all our AI agents.
- Features Implemented: 15+
- Cost Reduction: 30%
- Agents Monitored: 3
- Trace Coverage: 100%
Architecture
We integrated Langfuse into our existing DBaaS platform architecture by creating a three-layer abstraction: a utility layer (langfuse_utils.py) for direct SDK interactions, an enhanced layer (langfuse_enhanced.py) for high-level abstractions, and a prompt manager (prompt_manager.py) for centralized versioning. This layered approach allowed us to instrument all three existing agents (PainPointExtractorAgent, MarketGapGeneratorAgent, MarketIdeaExpanderAgent) with minimal code changes.
- Langfuse Client: Singleton SDK client for all Langfuse operations with connection pooling and error handling
- Langfuse Utils Layer: Core utility functions for traces, spans, generations, events, scores, and prompt management
- Langfuse Enhanced Layer: High-level abstractions with automatic scoring, user/session management, and enhanced trace creation
- Prompt Manager: Centralized prompt management with Langfuse UI integration and file-based fallback
- Cost Extraction: Automatic cost extraction from OpenRouter API responses
- Usage Tracking: Token usage extraction and tracking for all LLM generations
Results
- Cost Reduction: 30% reduction in AI operation costs through optimization insights
- Visibility: 100% trace coverage across all AI agents
- Prompt Management: Centralized prompt versioning enabling rapid iteration
- Quality Improvement: Automated scoring enabling continuous quality enhancement
- Time Savings: Reduced debugging time by 70% through comprehensive trace data
The Langfuse integration gave us complete visibility into our AI operations. We were able to identify and fix cost inefficiencies that saved us thousands of dollars per month.
— Engineering Lead, AI Platform Team
Read full case study →
- Category
- Frontend Development
- Tags
- React, TypeScript, Redux, Tailwind CSS, REST API, Dashboard, Admin Panel, Data Visualization
- Author
- Sunnykumar Lalwani — Principal Engineer - Backend and Systems Architecture
- Date
- Nov 2024
- Read time
- 14 min read
Summary: How we architected and built a comprehensive React-based dashboard and management system for enterprise clients, featuring real-time data visualization, role-based access control, and modular component architecture serving 5,000+ daily active users.
Overview
Our enterprise client needed a comprehensive dashboard system to manage their operations, users, and analytics across multiple departments. The existing system was built with legacy jQuery and was slow, unmaintainable, and lacked modern features. We designed and built a complete React-based solution using TypeScript for type safety, Redux Toolkit for state management, React Query for server state, and Tailwind CSS for styling. The dashboard features real-time data updates, interactive charts and tables, role-based access control, dark/light mode theming, and responsive design for mobile devices. The modular component architecture enables rapid feature development and easy maintenance.
- Daily Active Users: 5K+
- Page Load Improvement: 60%
- Components Built: 150+
- User Engagement Increase: 45%
Architecture
The dashboard follows a modular component architecture with clear separation of concerns. The presentation layer consists of reusable UI components built with React and styled with Tailwind CSS. The state management layer uses Redux Toolkit for global state and React Query for server state with automatic caching and refetching. The API layer provides a unified interface for all backend communications with request/response interceptors for authentication and error handling. Role-based access control is implemented at both component and route levels. The build system uses Vite for fast development and optimized production builds.
- React + TypeScript: Type-safe component development with comprehensive IDE support and compile-time error detection
- Redux Toolkit: Centralized state management with DevTools integration, async thunks, and slice-based organization
- React Query: Server state management with automatic caching, background refetching, and optimistic updates
- Tailwind CSS: Utility-first styling with custom design system, dark mode support, and responsive breakpoints
- React Router v6: Declarative routing with protected routes, nested layouts, and lazy loading for code splitting
- Recharts + AG Grid: Interactive data visualization with charts, graphs, and high-performance data tables
Results
- Performance: 60% faster page loads through code splitting and optimized rendering
- User Engagement: 45% increase in daily active users due to improved UX
- Development Speed: 50% faster feature development with reusable component library
- Maintainability: 80% reduction in bug reports through TypeScript and testing
The new React dashboard transformed how our team works. The speed improvements and intuitive interface have made everyone more productive. Our users love the real-time updates and responsive design.
— Product Manager, Enterprise Operations Team
Read full case study →
- Category
- Backend Development
- Tags
- Node.js, Express, PostgreSQL, Redis, Docker, REST API, Microservices, Performance
- Author
- Sunnykumar Lalwani — Principal Engineer - Backend and Systems Architecture
- Date
- Oct 2024
- Read time
- 16 min read
Summary: How we architected and built a scalable Node.js backend serving 2M+ daily API requests with 99.99% uptime, featuring horizontal scaling, intelligent caching, background job processing, and comprehensive monitoring for an enterprise SaaS platform.
Overview
Our enterprise SaaS platform required a robust backend capable of handling millions of API requests daily while maintaining sub-100ms response times. The previous PHP-based system couldn't handle traffic spikes and frequently experienced timeouts during peak hours. We rebuilt the backend using Node.js with Express, implementing a layered architecture with clear separation between controllers, services, and data access layers. The solution features connection pooling for PostgreSQL, Redis for caching and session management, Bull queues for background job processing, and PM2 cluster mode for utilizing all CPU cores. Docker containerization enables horizontal scaling across multiple instances behind a load balancer.
- Daily API Requests: 2M+
- Average Response Time: 50ms
- Concurrent Connections: 10K+
- Uptime Achieved: 99.99%
Architecture
The backend follows a layered architecture with Express handling HTTP requests, routing them through middleware for authentication and validation, to controllers that orchestrate business logic in service classes, which interact with the data layer through repositories. PostgreSQL serves as the primary database with connection pooling via pg-pool. Redis provides caching for frequently accessed data and session storage. Bull queues handle background jobs like email sending, report generation, and data processing. PM2 manages the Node.js cluster with automatic restarts and load balancing across CPU cores. The entire stack is containerized with Docker and orchestrated with Docker Compose for local development and Kubernetes for production.
- Express.js: Fast, unopinionated web framework with middleware pipeline for authentication, validation, and error handling
- PostgreSQL: Primary database with connection pooling, prepared statements, and transaction support for data integrity
- Redis: In-memory caching with 85% hit rate, session storage, and pub/sub for real-time features
- Bull Queues: Background job processing for async operations with retry logic, job scheduling, and monitoring dashboard
- PM2 Cluster: Process manager with cluster mode utilizing all CPU cores, automatic restarts, and zero-downtime reloads
- Docker + Kubernetes: Containerization for consistent environments and orchestration for horizontal scaling and self-healing
Results
- Response Time: Average response time reduced from 800ms to 50ms (94% improvement)
- Throughput: From 500 to 10,000+ concurrent connections without degradation
- Availability: 99.99% uptime achieved through clustering and auto-restart
- Cost Efficiency: 40% reduction in server costs through efficient resource utilization
The Node.js rebuild was transformational. Our old system would crash during sales events; now we handle 10x the traffic without breaking a sweat. The 50ms response times have noticeably improved user experience.
— CTO, Enterprise SaaS Platform
Read full case study →
- Category
- Case Study
- Tags
- Fantasy Sports, Cricket, Real‑time Auction, FastAPI, Next.js, WebSockets, Docker
- Author
- Likhith Kumar Masura — AI Context Engineer
- Date
- 2026-03-09
- Read time
- 6 min
- Live demo
- https://cricpredict.apexneural.cloud/
Summary: How we built a production‑ready, real‑time fantasy cricket auction system with smooth bidding, live timers, and team management for IPL 2026.
Overview
For IPL 2026 we needed more than a static fantasy scoreboard. The vision was a live, commissioner‑controlled auction room: nominate players, run 30‑second bid windows, track budgets and squads in real‑time, and make it simple for casual players to join via invite links. We evolved an earlier Google‑Sheets‑driven scoring app into a full fantasy auction platform built on FastAPI, PostgreSQL, Redis, and a Next.js 16 front‑end.
- Concurrent bidders per league: 20–50
- Bid latency (p95): < 300 ms
- Player pool: 200+ IPL 2026 players
- Time to import pool: < 1 minute
Architecture
The system is split into a FastAPI backend and a Next.js 16 frontend, both Docker‑deployed. PostgreSQL stores users, leagues, teams, auction state snapshots, and the player pool. Redis powers WebSocket fan‑out and distributed locks for bid processing. The frontend connects via secure WebSocket per league, rendering an auction board with current player, live countdown timer, bids, and skipped players. Admin flows (commissioner controls, league creation, invites) use REST APIs; bidding and timer events use WebSockets.
- Next.js 16 Frontend: Auction dashboard, commissioner controls, join‑by‑invite flow, and a polished countdown UI using React 19 and standalone output for containerized deployment.
- FastAPI Backend: Authentication, league and team management, player imports, auction orchestration, and health/metrics endpoints. Uses SQLAlchemy + Alembic for PostgreSQL.
- Auction Manager + WebSocket Gateway: Server‑authoritative in‑memory auction state per league, guarded by asyncio locks and Redis‑based bid locks; exposes a typed WebSocket protocol for bidding and timer events.
- Player Pool Import: Deterministic seed from `raw_ipl_2026.txt` with `Name|Role|Country` format, feeding the `PlayerMaster` table and league‑scoped `LeaguePlayer` records.
Features
- Live Auction Board: Real‑time view of current player, bid amount, highest bidder, and countdown timer for all participants.
- Commissioner Controls: Pause/resume timer, load next player, view skipped players, and enforce minimum team counts before starting.
- Invite‑based Leagues: Secure join links with per‑user team limits and role‑based permissions (commissioner vs team owner vs viewer).
Results
- Reduced admin overhead: Commissioners manage everything in‑app: invites, team creation, auction start/stop, and round progression—no more juggling spreadsheets during bidding.
- Fair and transparent bidding: Server‑side validation and single‑source‑of‑truth timers eliminated disputes about late bids, budgets, or timer resets.
- Production‑ready deployment: Dockerized FastAPI and Next.js frontends run behind a reverse proxy with `/health/ready` checks, making it easy to deploy and scale on modern PaaS platforms.
Running our IPL 2026 fantasy auction felt smoother than most commercial platforms. The live timer, clear budget view, and skipped‑player list kept everyone in sync, even with 20+ bidders online.
— League Commissioner, Private IPL 2026 League, Commissioner & Team Owner
Read full case study →
- Category
- Email Marketing
- Tags
- Email Campaigns, Hyperlink Engine, API, Marketing Automation, Node.js
- Author
- Praveen Jogi — AI Context Engineer
- Date
- 2024-03-09
- Read time
- 7 min read
- Live demo
- https://demo.example.com/email-campaigns
Summary: How we built a centralized endpoint that accepts raw email addresses and transforms them into branded, trackable hyperlinks — powering smarter, measurable email campaigns at scale.
Overview
Our email campaign system needed a reliable way to convert plain email addresses into branded, clickable hyperlinks tied to our website. We built a centralized API endpoint that accepts an email, validates it, wraps it with a website URL, and returns a formatted hyperlink ready to embed in any email campaign template — enabling click tracking, personalization, and campaign attribution at scale.
- Emails Processed Daily: 500K+
- Click-through Rate Improvement: 35%
- Campaign Setup Time Saved: 70%
- Hyperlink Generation Latency: <50ms
Architecture
The Hyperlink Engine exposes a single REST endpoint. It receives an email address, validates its format, generates a personalized hyperlink combining the email with the target website URL, appends UTM tracking parameters, and returns the final hyperlink for use in campaign templates. All links are logged for click tracking and analytics.
- Email Validation Layer: Validates incoming email format using RFC 5322 standards before any processing begins, rejecting malformed inputs early.
- Hyperlink Generator: Combines the validated email with the target website URL and appends UTM parameters for campaign source, medium, and content tracking.
- Link Registry: Stores generated hyperlinks in a database tied to the campaign ID, enabling click tracking and conversion attribution.
- Campaign Injector: Integrates with email template engines to automatically replace placeholder tokens with generated hyperlinks before dispatch.
Features
- Email Validation: RFC 5322 compliant email validation rejects malformed addresses before hyperlink generation.
- UTM Parameter Injection: Automatically appends campaign source, medium, and ID parameters to every generated hyperlink.
- Personalized Hyperlinks: Each email address generates a unique hyperlink enabling per-recipient tracking and personalized landing pages.
- Link Registry & Analytics: All generated links are stored and tied to campaign IDs for click tracking and conversion reporting.
Results
- Full Campaign Attribution: Every hyperlink carries UTM parameters, giving marketing teams precise data on which emails drove clicks and conversions.
- Eliminated Manual Link Building: What previously took hours of manual work per campaign is now handled automatically via a single API call.
- Personalized at Scale: Each recipient gets a unique hyperlink tied to their email, enabling personalized landing pages and A/B testing.
- Improved Deliverability: Validated emails and clean hyperlink formatting reduced bounce rates and spam flagging across all campaigns.
Before this engine, our team manually created links for every campaign. Now it's fully automated — we just pass the email list and the links are ready to go in seconds.
— Priya Nair, VP of Engineering, Apexneural
Read full case study →
- Category
- Fintech
- Tags
- Razorpay, Payment Gateway, Fintech, API Integration, Node.js
- Author
- Praveen Jogi — AI Context Engineer
- Date
- 2024-03-09
- Read time
- 8 min read
- Live demo
- https://demo.example.com/payments
Summary: How we unified all payment flows across our platform using Razorpay as the central payment orchestration layer — reducing failures by 40% and cutting integration time in half.
Overview
Our platform handled payments across subscriptions, one-time purchases, and marketplace payouts — each using different libraries and ad-hoc integrations. This created a maintenance nightmare. We consolidated everything into a Central Payment Gateway (CPG) backed by Razorpay, giving us a single source of truth for all transaction flows, webhooks, and reconciliation.
- Payment Success Rate: 99.2%
- Reduction in Failed Transactions: 40%
- Integration Time Saved: 60%
- Monthly Transactions Processed: 2.5M+
Architecture
The CPG sits between all internal services and Razorpay's API. It abstracts payment creation, status polling, webhook verification, and refund handling into a unified internal SDK. Services never call Razorpay directly — they go through CPG, which enforces retry logic, idempotency, and audit logging.
- Payment Orchestrator: Routes payment requests to the correct Razorpay method (orders, subscriptions, payment links) based on context.
- Webhook Processor: Verifies HMAC signatures, deduplicates events, and fans out to internal services via an event bus.
- Idempotency Layer: Uses Redis to track in-flight and completed requests, preventing duplicate charges on retries.
- Reconciliation Engine: Periodically syncs transaction states between our DB and Razorpay's settlement reports.
Features
- Multi-method Support: Handles UPI, cards, netbanking, wallets, and EMI through a single unified API surface.
- Webhook Reliability: HMAC-verified, deduplicated webhook processing with dead-letter queue for failed handlers.
- Refund Automation: Policy-based refund engine automatically triggers and tracks Razorpay refund requests.
- Settlement Reconciliation: Automated daily reconciliation against Razorpay settlement reports with discrepancy alerting.
Results
- Unified Observability: All payment events flow through a single service, giving us centralized logging, alerting, and dashboards for the first time.
- Faster Incident Response: MTTR for payment incidents dropped from 45 minutes to under 10 minutes due to structured logs and webhook replay capability.
- Easier Compliance: PCI-DSS scope was dramatically reduced — only CPG touches payment data, isolating risk from other services.
- Team Velocity: New product teams integrate payments in hours using our internal SDK instead of reading Razorpay docs from scratch.
Before the CPG, every team had their own Razorpay integration. Debugging a failed payment meant checking 4 different codebases. Now it's one place, one log, one truth.
— Priya Nair, VP of Engineering, Apexneural
Read full case study →
- Category
- Cybersecurity
- Tags
- Cybersecurity, OWASP Top 10, SOC Compliance, AI Security Scanner, DevSecOps
- Author
- Devulapelly Kushal Kumar — AI Context Engineer
- Date
- 2026-03-10
- Read time
- 9 min read
- Live demo
- /case-studies
Summary: How we built a SaaS platform where users simply upload a website URL and instantly receive a complete OWASP Top 10 vulnerability report along with infrastructure security insights, helping teams move toward SOC-level compliance.
Overview
Modern web applications face constant cybersecurity threats ranging from injection attacks to misconfigured cloud infrastructure. However, most security audits are still manual, expensive, and slow. To solve this problem, we built an AI-powered SaaS platform where users simply submit a website URL. The system automatically scans the application, detects vulnerabilities aligned with OWASP Top 10 standards, evaluates infrastructure exposure, and generates a structured security report that organizations can use to improve their security posture and move toward SOC-level compliance.
- Average Scan Time: 90 seconds
- OWASP Vulnerabilities Detected: Top 10 Coverage
- Websites Scanned Monthly: 50K+
- Security Insights Generated: 200K+
Architecture
The platform operates as a modular security scanning pipeline. Once a user submits a URL, the system launches automated crawlers and scanners that analyze application endpoints, infrastructure exposure, and security headers. AI models then classify vulnerabilities and generate human-readable security reports.
- Website Crawler: Discovers pages, APIs, and endpoints within the target website to build a full scanning map.
- OWASP Vulnerability Engine: Detects vulnerabilities such as injection attacks, broken authentication, and security misconfigurations.
- Infrastructure Analyzer: Identifies server technologies, CDN providers, open ports, SSL configuration, and DNS exposure.
- AI Risk Classifier: Uses machine learning to classify detected issues by severity and generate contextual remediation guidance.
Features
- OWASP Top 10 Detection: Automatically identifies vulnerabilities including injection, broken authentication, and security misconfigurations.
- Infrastructure Intelligence: Analyzes hosting providers, CDN usage, SSL configurations, DNS exposure, and open ports.
- AI-Powered Risk Scoring: Machine learning models classify vulnerabilities based on severity and real-world exploitability.
- Automated Security Reports: Generates detailed reports with vulnerability descriptions, severity scores, and recommended fixes.
Results
- Faster Security Audits: Security scanning that previously required hours of manual penetration testing can now be completed automatically in under two minutes.
- Improved Security Visibility: Organizations receive clear reports highlighting OWASP vulnerabilities, infrastructure exposure, and remediation guidance.
- SOC Readiness: The platform helps companies move toward SOC compliance by identifying infrastructure risks and security gaps.
- Developer-Friendly Security: Reports are generated in both technical and simplified formats so developers and business teams can understand them easily.
This platform turned a full-day manual security audit into a 90-second automated scan. Our DevOps team now runs security checks on every release.
— Rahul Sharma, Head of Engineering, SecureCloud
Read full case study →
- Category
- AI / Conversational Commerce
- Tags
- RAG, LLM, WhatsApp, Telegram, FastAPI, Multi-Tenant SaaS, Python
- Author
- Parmeet Singh Talwar — AI Context Engineer
- Date
- Sep 2025
- Read time
- 8 min read
- Live demo
- https://app.unify.ai
Summary: How we built Kala — an AI-powered sales assistant that speaks Hinglish, analyses customer photos, and closes saree sales 24/7 across WhatsApp, Instagram, and Telegram.
Overview
A leading D2C saree retailer was losing sales every day because customer queries on WhatsApp and Instagram went unanswered after business hours. Agents were overwhelmed managing hundreds of chat threads manually. We built **Unify** — a multi-tenant SaaS platform with an AI persona called **Kala** — that acts like a knowledgeable in-store salesperson: she understands Telugu, Hinglish, and English; she can look at a photo a customer sends and find the matching saree in a 5,000-product catalog; and she hands off to a human agent the moment sentiment dips or a refund is requested.
- Channels Supported: 3
- Languages Handled: 4 (EN / HI / TE / Hinglish)
- Products Indexed in RAG: 5,000+
- Avg. Response Latency: < 2s
- Human Escalation Rate: ~15%
- Uptime Target: 99.9%
Architecture
Unify is built around an **Omnichannel Gateway** that normalises payloads from WhatsApp, Instagram, and Telegram into a single internal Message schema. Every inbound message is routed through a JWT-authenticated multi-tenant context resolver that scopes all data and AI config to the correct organisation. The AI pipeline runs a hybrid RAG retrieval (BM25 lexical + sentence-transformer semantic search fused with Reciprocal Rank Fusion) before sending the context to Gemini 2.0 Flash for generation. A real-time WebSocket layer pushes escalations and new messages to the React dashboard instantly.
- Omnichannel Gateway: Unified webhook endpoints that normalise WhatsApp, Instagram, and Telegram payloads into a standard internal Message schema, with signature verification and multi-tenant context injection.
- Hybrid RAG Engine: BM25 (rank-bm25) lexical retrieval fused with Sentence-Transformer semantic search via Reciprocal Rank Fusion (RRF). NLU entities (color, fabric, SKU, price range) are injected into the search query. A greedy diversity filter ensures results span different colors and fabrics.
- LLM Orchestrator: Gemini 2.0 Flash via OpenRouter. Manages system prompt versioning, conversation history compression, language mirroring (Hinglish ↔ Telugu ↔ English), and brand guardrails (2–4 sentence replies, CTA in every message).
- Vision Service: Multimodal image analysis: customer photos are base64-encoded and sent to the LLM with a specialised prompt that extracts colour, fabric, and pattern tags, which are then used to query the RAG catalog.
- Escalation Engine: Rule-based scoring that triggers human handoff on keyword triggers ("refund", "talk to human"), negative sentiment threshold breaches, or consecutive AI failure turns. Sets human_controlled flag and pushes a WebSocket event to the Agent Inbox.
- Unified Agent Inbox: React + Vite dashboard with a 3-column inbox (list | thread | context panel). Real-time red badge alerts via WebSocket. Agents can take over, reply via WhatsApp API, attach products, and resolve / hand back to AI.
Features
- Omnichannel Inbox: Single dashboard to manage WhatsApp, Instagram, and Telegram conversations. Real-time WebSocket push for new messages and escalation alerts.
- Hybrid RAG Engine: BM25 + Sentence-Transformer semantic search fused with Reciprocal Rank Fusion. Diversity filter ensures variety in recommendations.
- Vision AI Product Matching: Customers can send a reference photo; multimodal LLM extracts tags and queries the catalog for visually similar sarees.
- Multilingual Support: Native support for English, Hindi, Telugu (script & transliterated), and Hinglish with automatic language mirroring.
- Smart Escalation: Rule-based and sentiment-aware escalation to human agents. Human-controlled flag pauses AI and unlocks agent reply box.
- System Prompt Versioning: Prompts are stored and versioned in the database. Rollback to any previous version without redeployment.
- HostFlow — Cleaning Job Management: Telegram-based cleaner workflow: job dispatch, photo uploads, manager review/approval, and rework loops — all automated.
- Multi-Tenancy: Every query, embedding, and conversation is scoped by org_id. Strict logical data isolation between organisations.
Results
- 85% Queries Resolved by AI: Only ~15% of conversations required human intervention, down from 100% manual handling before deployment.
- 24/7 Sales Coverage: Kala operates across all time zones on WhatsApp, Instagram, and Telegram with sub-2-second response times.
- Multilingual by Design: Language detection and mirroring means customers can type in Telugu or Hinglish and receive a perfectly matched reply in kind.
- Visual Product Matching: Vision AI enables customers to send a reference photo and get matched sarees from a 5,000+ product catalog — a feature impossible with keyword-only search.
- Zero-Setup RAG Updates: The catalog can be refreshed from Supabase or a CSV drop. The RAG index rebuilds automatically on the next query with no server restart required.
- Multi-Tenant Isolation: Every query is scoped by org_id, ensuring Brand A's catalog and conversations are never visible to Brand B.
Before Unify, our team was manually copy-pasting product links at 11 PM. Now Kala handles 85% of queries end-to-end — she even matches customers to sarees when they send us a blurry reference photo from Pinterest.
— Store Manager, Store Manager, D2C Saree Retail Brand
Read full case study →
- Category
- AI Product Case Study
- Tags
- AI, storytelling, childrens-books, automation, react, python, fastapi, tailwind
- Author
- Annie Siri — AI Context Engineer
- Date
- 2026-03-06
- Read time
- 6 min read
- Live demo
- http://apexwingbooks.com
Summary: How ApexWing Books turns a simple storyline choice into a fully generated AI storybook that arrives directly in the parent’s mail.
Overview
ApexWing Books is an AI-powered platform that lets parents create personalized storybooks for their children in just a few clicks. Parents choose a child profile, pick a storyline that fits their kid’s personality, and confirm.
From that point on, the platform handles everything automatically: generating the story, creating illustrations for each page, assembling a beautiful PDF, and emailing a secure link to the finished book. The result is a premium experience that feels simple and delightful on the surface, powered by a sophisticated AI pipeline behind the scenes.
- Time to complete flow: < 2 minutes
- Pages per book (incl. cover & extras): 18–22
- Extra clicks after storyline: 0
Architecture
The solution uses a React + Vite frontend styled with a Lovable-inspired Tailwind UI, backed by a FastAPI service layer. The frontend focuses on guiding parents through a short creation funnel and clearly setting expectations about email delivery. The backend orchestrates AI calls for story and image generation, tracks book state, and produces a high-quality PDF that can be opened on any device.
- Frontend (React + Vite + Tailwind): Delivers a polished UI with a modern home page, a guided creation flow, and clear status messaging about when the book link will arrive by email.
- Backend (FastAPI + services): Provides APIs for child profiles, series and storyline selection, story generation, image prompts, and PDF creation, all designed to run in a single automated pipeline.
- AI Story & Image Engine: Generates a multi-page story script and corresponding illustrations for each page—cover, publisher page, story pages, and collection/back pages.
- Email & Delivery Layer: Once the PDF is generated and stored, the system sends a notification email with a secure link to view and download the finished book.
Features
- Automated Storybook Generation: End-to-end creation of story text, illustrations, and a polished PDF triggered by a single storyline choice.
- Email-Based Delivery: Parents receive a secure link to the finished book via email, with no need to monitor the generation process.
- Modern, Child-Friendly UI: A Lovable-inspired React/Tailwind interface that feels premium and approachable for parents and kids.
Results
- Ultra-simple experience for parents: Reduced visible steps to a minimum: choose a storyline, confirm, and wait for the email with the book link.
- Reliable, repeatable generation: Every book goes through the same automated process, guaranteeing a consistent structure and visual style.
- Production-ready pipeline: Architecture designed from day one to run without manual intervention, so the system can scale to many users.
I picked a storyline for my daughter and then just waited for the email. The finished book looked amazing, and I didn’t have to worry about any complicated settings.
— Priya S., Parent of a 6-year-old
Read full case study →