

Project Overview
The FireCrawl Agent solves the 'staleness' problem in RAG by integrating real-time web crawling. We built a persistent system where users can upload PDFs and engage in a dialogue that automatically crawls the web for missing context. The system was recently migrated to PostgreSQL to support multi-user sessions and high-concurrency workloads.
System Architecture
The system utilizes a modern full-stack architecture with a FastAPI backend and a React/TypeScript frontend. It orchestrates complex agentic flows using LlamaIndex Workflows, persisting structured data in PostgreSQL and vector embeddings in a persistent ChromaDB store.
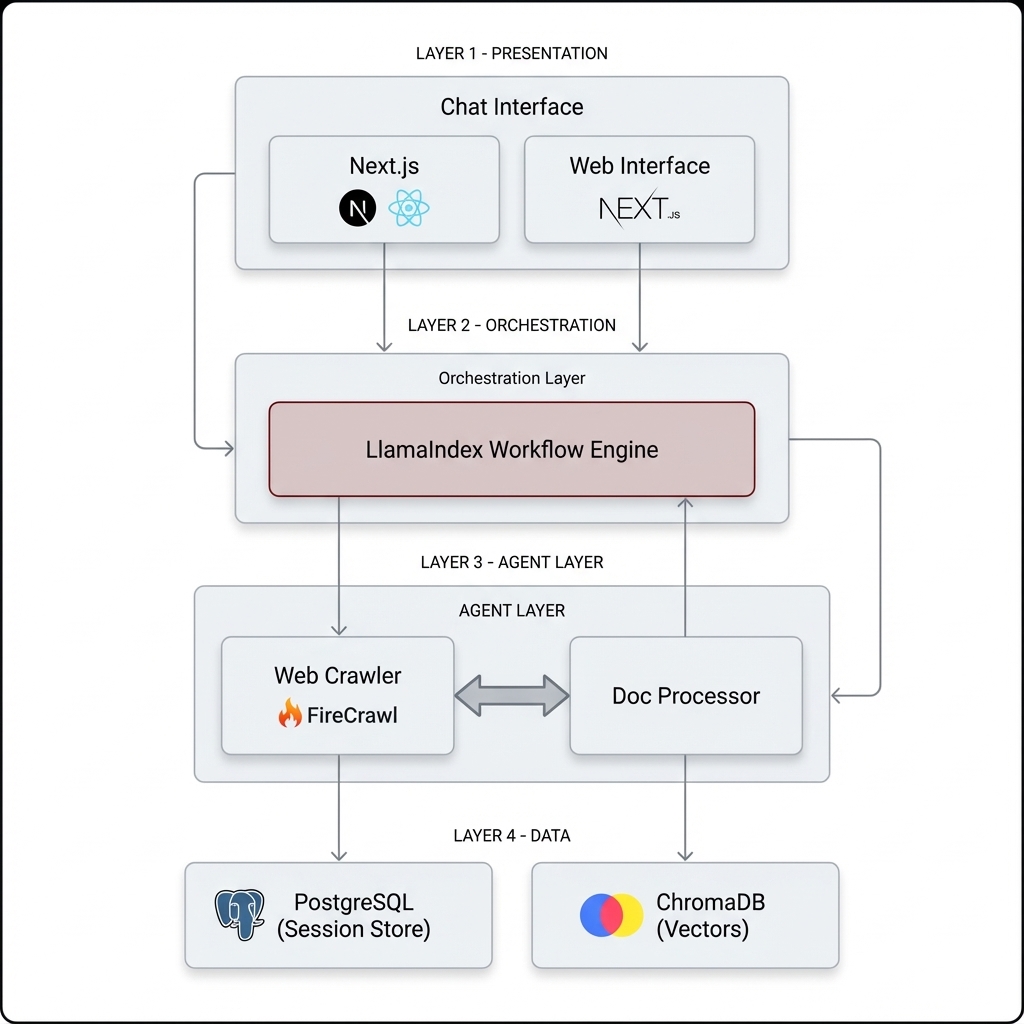
Orchestrator
LlamaIndex Workflows for state-managed agent runs
Web Scraper
FireCrawl for intelligent, LLM-ready web ingestion
Primary Store
PostgreSQL with SQLAlchemy for session persistence
Vector Store
ChromaDB for local document semantic indexing
Implementation Details
Code Example
async def process_document(self, file_path: str):
# Setup persistent ChromaDB client
chroma_client = chromadb.PersistentClient(path='./chroma_db')
chroma_collection = chroma_client.get_or_create_collection('demo')
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# Create Agentic Workflow with FireCrawl tools
workflow = AgenticRAGWorkflow(
index=index,
firecrawl_api_key=os.environ['FIRECRAWL_API_KEY'],
timeout=249
)
return workflowAgent Memory
When migrating from SQLite to PostgreSQL, always ensure UUID types match across the schema to prevent bind-parameter mismatches during high-concurrency async operations.
Workflow
Authentication: User signs in via premium UI.
Ingestion: PDF uploaded and embedded into persistent storage.
Query: User asks a question in the chat interface.
Agentic Loop: System decides whether to use local PDF data or crawl via FireCrawl.
Result: Final synthesized answer with full logs returned to user.

Results & Impact
"The integration of FireCrawl with our local research PDFs turned a week of browsing into a 5-minute chat session."
Scale
Ready for 10,000+ concurrent sessions
UX
Sub-2s response time for vector retrieval
Persistence
100% session recovery after server restarts
About the Author
Contributors

Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.