NotebookLM Clone - Document-Grounded AI Assistant
An open-source implementation of Google's NotebookLM that grounds AI responses in your documents with accurate citations, featuring multi-modal processing, conversational memory, and AI podcast generation.


Project Overview
Document-based AI assistants often struggle with accuracy and citation. Users need to trust AI responses, especially when working with critical documents like research papers, legal documents, or technical manuals. This project builds an open-source NotebookLM clone that ensures every AI response is grounded in source documents with precise citations. The system processes multiple document types (PDFs, audio, video, web content), maintains conversational context through temporal knowledge graphs, and even generates AI podcasts from documents.
System Architecture
The system follows a modular RAG (Retrieval-Augmented Generation) architecture with a Streamlit frontend orchestrating specialized processing components. Each component handles a specific document type or processing stage, all connected through a central vector database and memory layer for unified semantic search and context retention.
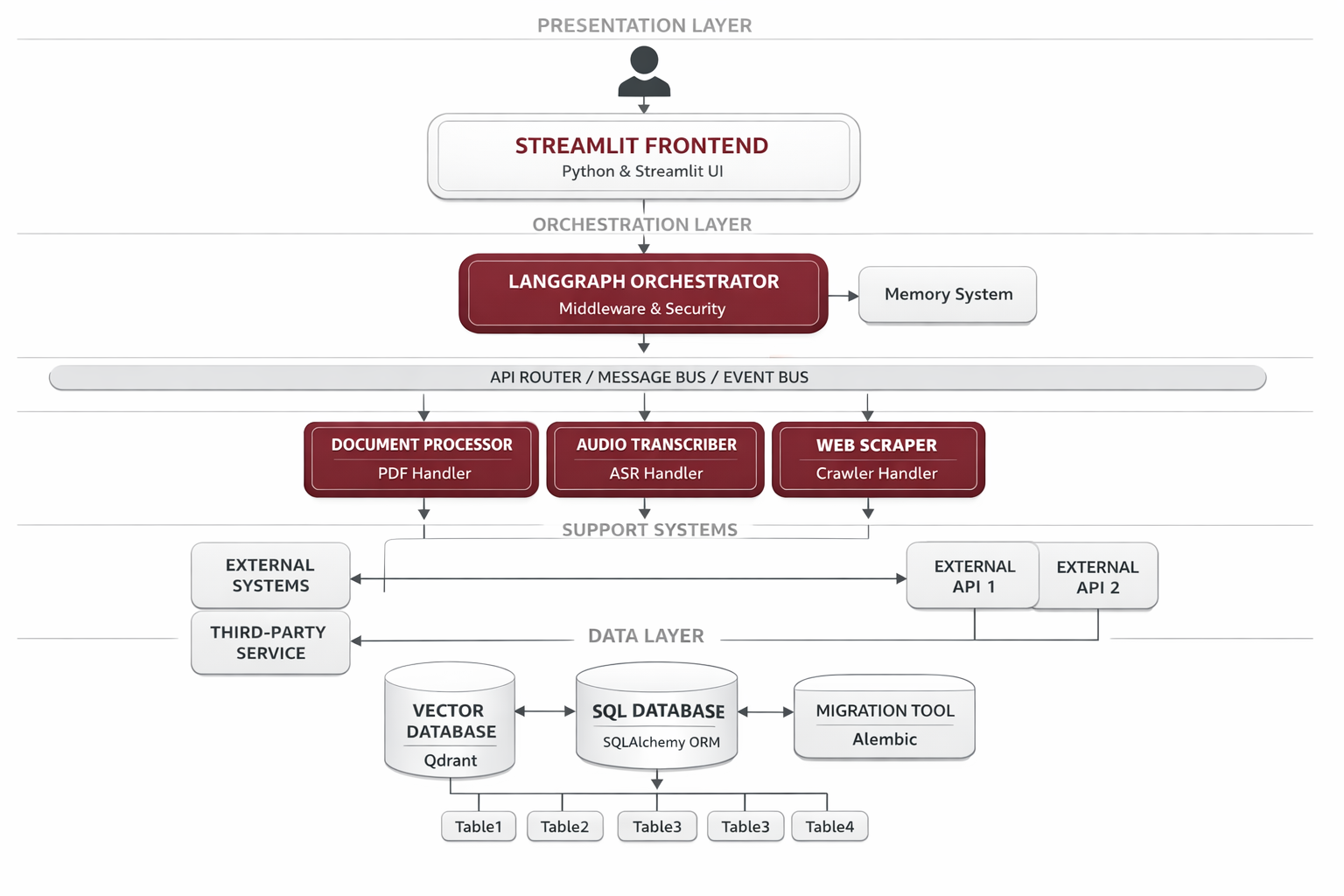
Document Processor
PyMuPDF-based processing for PDF, TXT, and Markdown files with metadata extraction
Audio Transcriber
AssemblyAI integration for audio transcription with speaker diarization
YouTube Transcriber
Video-to-text conversion with timestamp-based chunking
Web Scraper
Firecrawl-powered content extraction from websites
Embedding Generator
Local HuggingFace model for vector embeddings generation
Qdrant Vector DB
Efficient vector storage and semantic search with citation metadata
RAG Generator
OpenRouter LLM integration for cited response generation
Memory Layer
Zep temporal knowledge graphs for conversational context
Podcast Generator
Script generation and Coqui TTS for multi-speaker podcast creation
Implementation Details
Code Example
# RAG Pipeline with Citation Metadata
class RAGGenerator:
def generate_response(self, query: str, conversation_history: List[Dict]) -> Dict:
# Embed query for semantic search
query_embedding = self.embedding_generator.embed_query(query)
# Retrieve relevant chunks with metadata
results = self.vector_db.search(
query_embedding,
top_k=5,
include_metadata=True # Page numbers, timestamps, sources
)
# Get conversation context from memory
memory_context = self.memory.get_context(session_id)
# Generate cited response using retrieved chunks
response = self.llm.generate(
query=query,
context=results,
memory=memory_context,
citations=True # Enforce citation format
)
# Store conversation in memory layer
self.memory.add_message(query, response)
return responseAgent Memory
Using overlapping text chunks (with 50-100 token overlap) ensures that context isn't lost at chunk boundaries. This dramatically improves retrieval quality for complex queries that span multiple paragraphs.
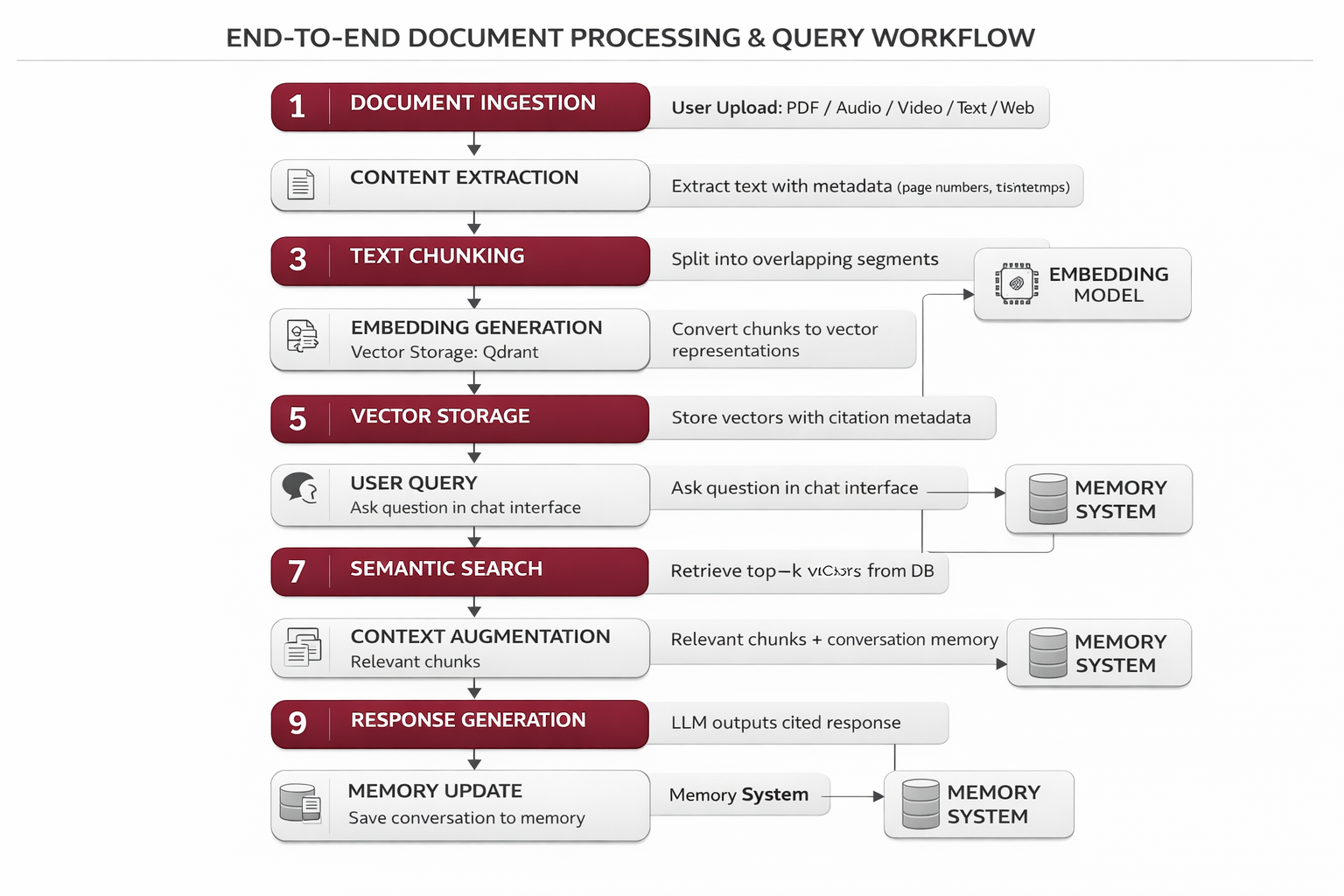
Workflow
Document Ingestion: User uploads PDF, audio, video, text, or web URL
Content Extraction: Content extracted with metadata (page numbers, timestamps)
Text Chunking: Text split into overlapping segments preserving context
Embedding Generation: Chunks converted to vector representations
Vector Storage: Vectors stored in Qdrant with citation metadata
User Query: User asks question in chat interface
Semantic Search: Query embedded and top-k relevant chunks retrieved
Context Augmentation: Retrieved chunks + conversation memory combined
Response Generation: LLM generates cited response with references
Memory Update: Conversation saved to Zep for future context
Results & Impact
"NotebookLM Clone transformed how our research team works with academic papers. The citation accuracy and multi-modal support means we can process interviews, papers, and conference videos all in one place."
Accuracy
100% citation traceability to source documents
Efficiency
3x faster document review and analysis
Versatility
Supports 7+ document formats seamlessly
Memory
Temporal knowledge graphs remember full context
About the Author
Ramya
Senior Engineer - Integrations and Applied AI
Apex Neural
12+ years building scalable AI-driven and web applications across healthcare, fintech, and enterprise. Deep expertise in multi-agent systems, LLM workflows, RAG pipelines, API orchestration, payment integrations, and document intelligence (OCR and structured extraction).
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.