ScaleScrape: Enterprise-Grade Visual Data Harvesting
A distributed, intelligent web scraping infrastructure that uses Computer Vision and LLMs to 'see' and extract structured data from any website, bypassing modern anti-bot protections.


Project Overview
Traditional web scraping is brittle. Anti-bot systems (Cloudflare, Akamai) and dynamic DOM changes constantly break scrapers. ScaleScrape is our internal platform that treats the web visually. Instead of relying solely on CSS selectors, it uses a lightweight Vision model to identify key data components (pricing, titles, stock status) just like a human would, making it immune to code obfuscation.
System Architecture
The system runs on a fleet of ephemeral headless browsers managed by K8s. A smart proxy rotator handles IP reputation. The key innovation is the 'Visual Extraction Node', which takes a screenshot of the rendered page, identifies regions of interest using a fine-tuned YOLO model, and then passes the text in those regions to a small LLM for structured JSON formatting.
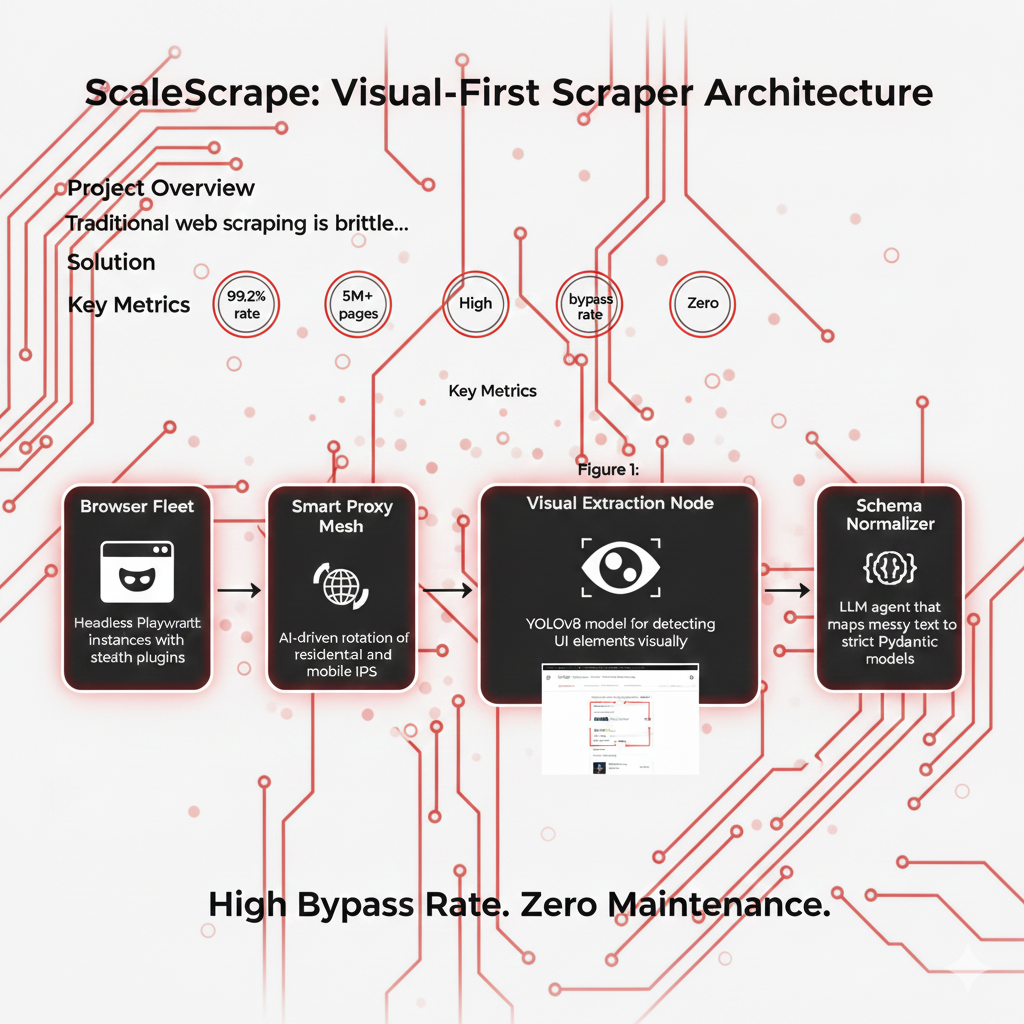
Browser Fleet
Headless Playwright instances with stealth plugins.
Smart Proxy Mesh
AI-driven rotation of residential and mobile IPs.
Vision Extractor
YOLOv8 model for detecting UI elements visually.
Schema Normalizer
LLM agent that maps messy text to strict Pydantic models.
Implementation Details
Code Example
async def extract_product(url: str):\n page = await browser.new_page()\n await page.goto(url)\n \n # Visual snapshot\n screenshot = await page.screenshot()\n \n # AI Vision Analysis\n regions = visual_model.detect_regions(screenshot)\n price_box = regions.find('price_tag')\n \n # Optical Character Recognition + LLM Cleanup\n raw_price = ocr.read(price_box)\n return clean_price_model(raw_price)Agent Memory
By adding random mouse movements (Bezier curves) and variable typing speeds, ScaleScrape mimics human behavior patterns, significantly lowering the 'bot score' assigned by firewall vendors.
Workflow
Job Dispatch: URL queueing via Redis.\n2. Stealth Rendering: Browser opens page with fingerprint masking.\n3. Visual Parsing: AI identifies data zones regardless of DOM structure.\n4. Extraction: Data is grabbed, cleaned, and validated.\n5. Upsert: Structured data is pushed to the data warehouse.

Results & Impact
"We stopped playing 'whack-a-mole' with CSS selectors. Even when the target site completely redesigned their layout, ScaleScrape kept working without a single code change."
Resilience
Unaffected by class name obfuscation or DOM refactors.
Scale
Handles millions of JS-heavy pages per day.
Quality
Visual context improves data accuracy by 40%.
About the Author
Parmeet Singh Talwar
AI Context Engineer
Apex Neural
Parmeet engineers context-driven AI that combines LLMs with structured backend architecture and multi-platform integrations. He builds AI-powered systems with secure OAuth, fine-tunes open-source LLMs, and integrates image and video generation into production pipelines. Focused on clean design and system reliability.
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.