

Project Overview
Processing complex documents like financial reports and technical manuals is a major hurdle for RAG systems. This project implements a world-class pipeline using Ground X's X-Ray analysis. Unlike standard OCR, this system understands the relationship between figures, tables, and text, creating a rich narrative and structured JSON output. This output is then engineered into a context-aware chat interface powered by OpenRouter.
System Architecture
The system utilizes a Streamlit frontend for document ingestion and interactive visualization. The CORE logic is handled by Ground X for parsing and bucket management. Processed data is fetched as 'X-Ray' objects, which include narratives and keywords. These objects are used to enrich LLM prompts via OpenRouter, providing highly accurate document metadata and interactive Q&A.
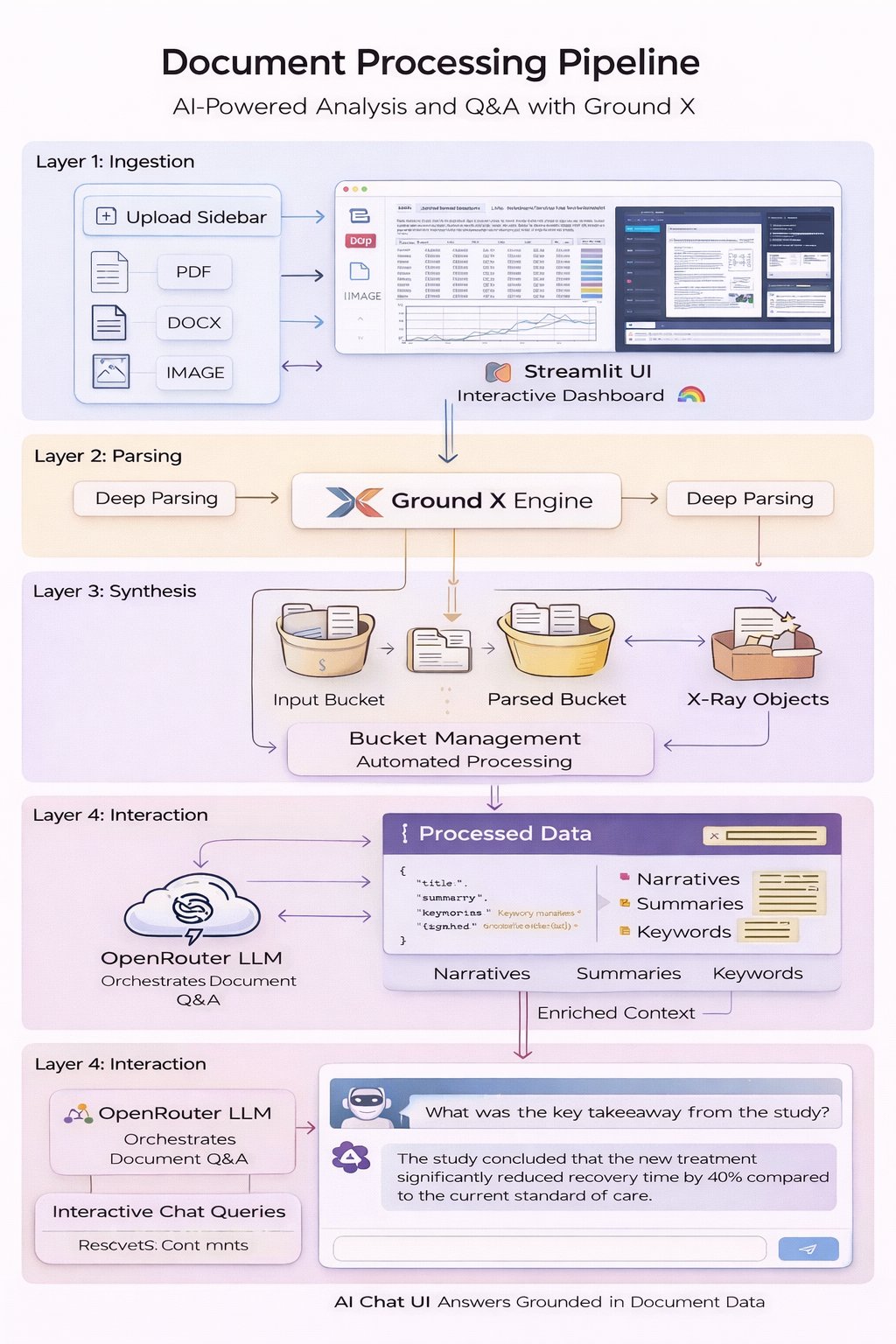
Ground X Engine
Handles high-fidelity parsing and X-Ray analysis.
Streamlit UI
Interactive dashboard for uploads and results exploration.
OpenRouter LLM
Orchestrates document-based Q&A and narrative synthesis.
Bucket Management
Automated organization of raw and processed document assets.
Implementation Details
Code Example
import groundx\n\ndef process_document(file_path):\n # Create bucket and upload document\n bucket = client.buckets.create(name='Case Study Bucket')\n process = client.documents.upload(file_path, bucket_id=bucket.id)\n \n # Retrieve X-Ray analysis\n analysis = client.documents.get_xray(process.id)\n return analysis['narrative_summary']Agent Memory
Leveraging Ground X's narratives instead of raw text chunks significantly improves LLM performance by providing pre-synthesized document structure and key highlights.
Workflow
Ingestion: User uploads a PDF or image via the sidebar.\n2. Processing: Ground X performs deep parsing and X-Ray analysis.\n3. Synthesis: Narratives, summaries, and keywords are extracted.\n4. Interaction: User asks questions; LLM uses Ground X context to provide grounded answers.

Results & Impact
"This pipeline extracted data from our most complex multi-column tables with zero errors. It's the first time we haven't had to manually verify document parsing."
Precision
Industry-leading parsing of multi-modal document layouts.
Insight Speed
Reduces document review time by up to 80%.
Data Richness
Extracts keywords, summaries, and structured metadata automatically.
About the Author
Contributors

Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.