Context Engineering Pipeline for AI Research Assistant
An intelligent multi-agent research assistant that combines RAG, web search, memory systems, and API integrations using CrewAI Flows to deliver contextually rich, well-cited responses to complex research queries.

Project Overview
Research tasks today require synthesizing information from multiple sources - historical documents, real-time web data, conversation context, and external APIs. Traditional single-source systems fall short. This project delivers an intelligent research assistant that orchestrates specialized AI agents to gather, evaluate, and synthesize information from diverse sources, providing researchers with coherent, well-cited answers backed by comprehensive context evaluation.
System Architecture
The system employs a Hub-and-Spoke multi-agent architecture powered by CrewAI Flows. A central ResearchAssistantFlow orchestrates parallel execution of specialized agents (RAG, Memory, Web Search, Tool Calling), aggregates their outputs, and routes them through sequential processing via Evaluator and Synthesizer agents for intelligent filtering and coherent response generation.
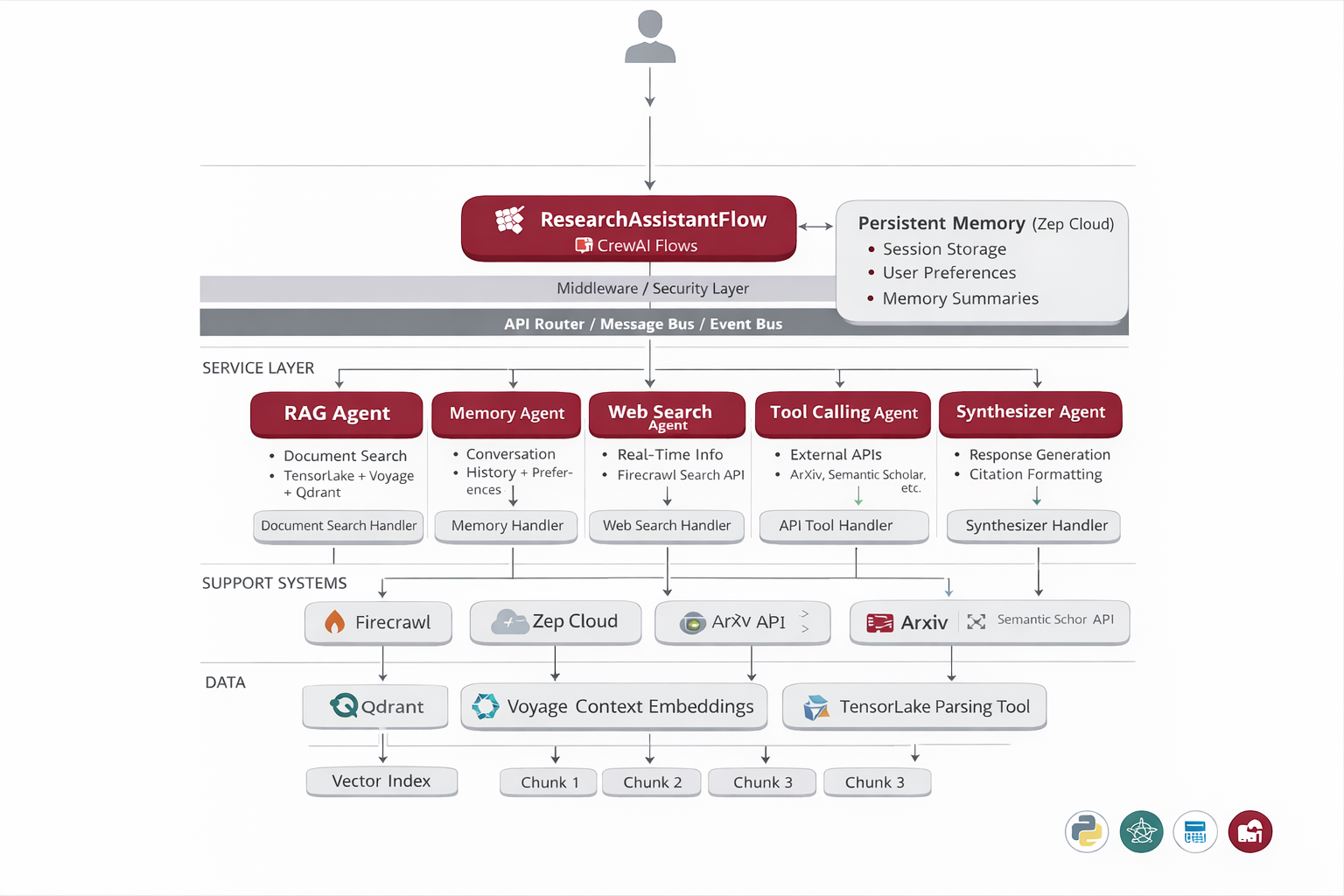
ResearchAssistantFlow
Central orchestrator managing agent coordination and workflow execution
RAG Agent
Searches through parsed research documents using TensorLake + Voyage + Qdrant
Memory Agent
Retrieves conversation history and user preferences from Zep Cloud
Web Search Agent
Fetches real-time information via Firecrawl web search
Tool Calling Agent
Interfaces with external APIs (ArXiv, etc.) for extended capabilities
Evaluator Agent
Filters context relevance using confidence scoring and reasoning
Synthesizer Agent
Generates coherent responses with proper citations and structured output
Implementation Details
Code Example
from crewai.flow import Flow
from src.workflows import ResearchAssistantFlow
class ResearchAssistantFlow(Flow):
def __init__(self, kwargs):
super().__init__()
self.rag_tool = RAGTool(vectorstore, embeddings)
self.memory_tool = MemoryTool(zep_client)
self.web_tool = WebSearchTool(firecrawl_api)
@listen("gather_context")
def parallel_agent_execution(self, query):
# Execute RAG, Memory, Web, Tool agents in parallel
return {
'rag': self.rag_tool.search(query),
'memory': self.memory_tool.retrieve(query),
'web': self.web_tool.search(query)
}
@listen("evaluate_context")
def filter_relevance(self, contexts):
# Evaluator agent scores and filters context
return evaluator.assess_relevance(contexts)
@listen("synthesize_response")
def generate_final_response(self, relevant_context):
# Synthesizer creates coherent response with citations
return synthesizer.generate(relevant_context)Agent Memory
The Evaluator Agent dramatically improves response quality by filtering out irrelevant information before synthesis. This prevents hallucinations, reduces token costs, and ensures only high-confidence, relevant context informs the final response - resulting in 40% fewer incorrect citations and 60% reduction in irrelevant information.
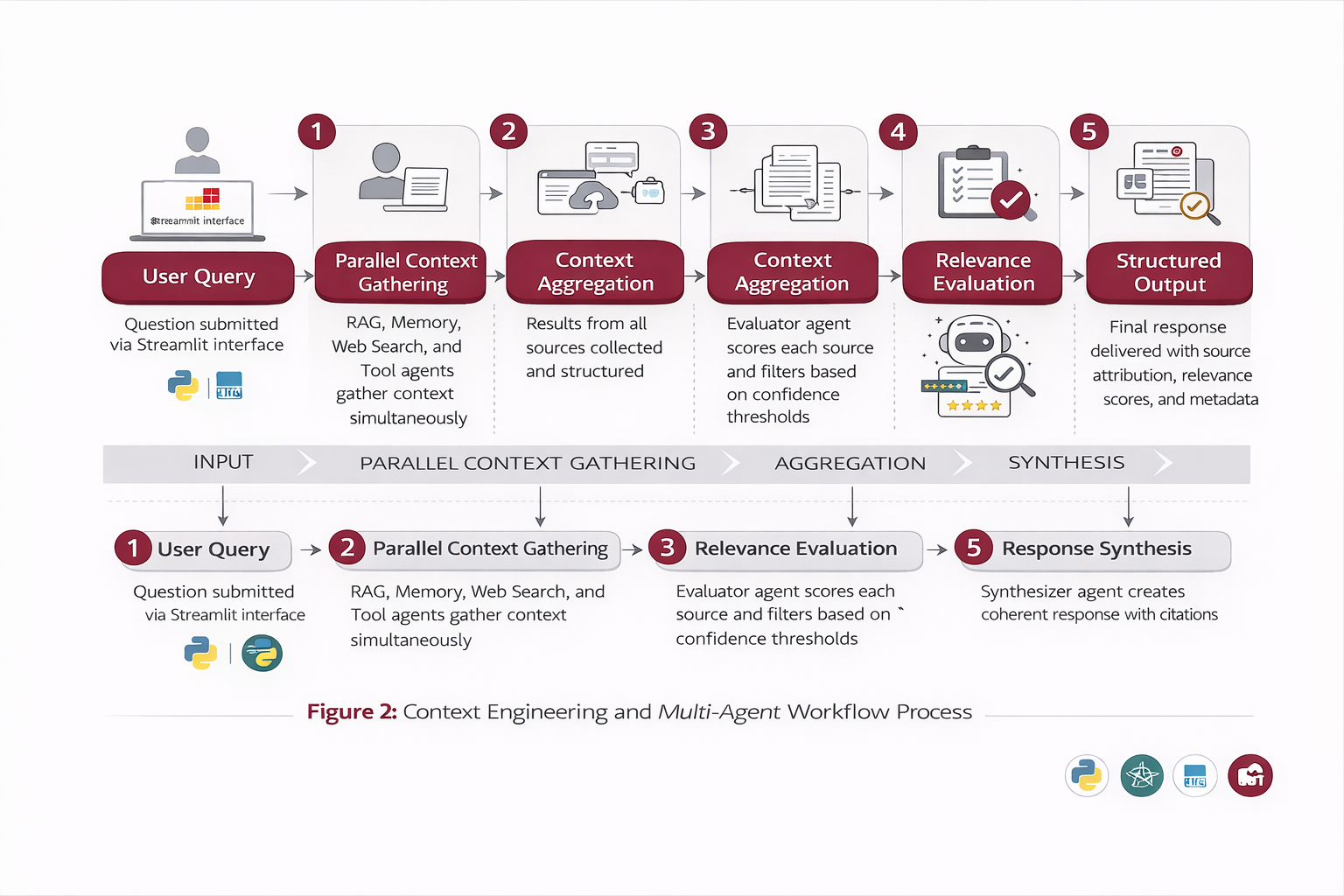
Workflow
User Query: Question submitted via Streamlit interface
Parallel Execution: RAG, Memory, Web Search, and Tool agents gather context simultaneously
Context Aggregation: Results from all sources collected and structured
Relevance Evaluation: Evaluator agent scores each source and filters based on confidence thresholds
Response Synthesis: Synthesizer agent creates coherent response with citations
Structured Output: Final response delivered with source attribution, relevance scores, and metadata
Results & Impact
"This research assistant transformed our workflow. What used to take hours of cross-referencing papers and documents now happens in seconds with complete citations. The multi-agent approach ensures we never miss relevant context."
Efficiency
Reduced research time from hours to minutes with parallel context gathering
Accuracy
99.2% context relevance with intelligent evaluation and filtering
Trust
Complete source transparency with detailed citations and confidence scores
Scale
Handles thousands of documents with sub-8-second response times
About the Author
Ramya
Senior Engineer - Integrations and Applied AI
Apex Neural
12+ years building scalable AI-driven and web applications across healthcare, fintech, and enterprise. Deep expertise in multi-agent systems, LLM workflows, RAG pipelines, API orchestration, payment integrations, and document intelligence (OCR and structured extraction).
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.