RunPod & The Serverless GPU Revolution
How RunPod is democratizing AI compute by offering serverless GPU containers. A deep dive into auto-scaling LLM inference endpoints without managing Kubernetes clusters.


Project Overview
Traditional cloud providers (AWS, GCP) are expensive and complex for transient AI workloads. RunPod changes the game by offering 'Serverless Pods'—Docker containers that wake up only when a request comes in. We migrated our entire text-to-image pipeline to RunPod, reducing idle costs by 80% while maintaining sub-second cold starts.
System Architecture
The architecture consists of a custom Docker image containing the model weights (baked in for speed). This image is deployed to RunPod's Serverless platform. A global load balancer routes API requests to available pods. If no pods are active, RunPod provisions one instantly from a 'warm pool'. Network Volumes provide persistent storage for LoRA adapters across pod restarts.
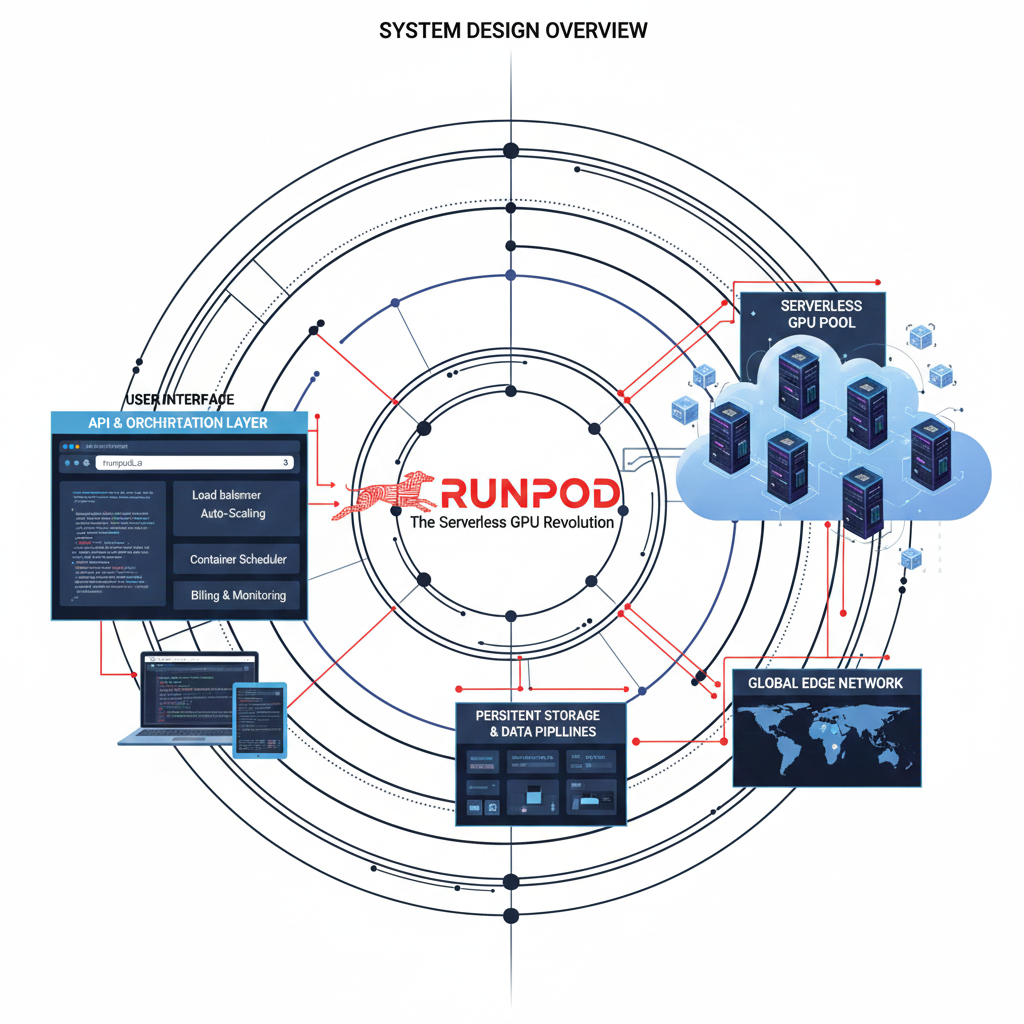
Custom Handler
Python entrypoint function that loads the model.
Network Volume
Shared high-speed storage for large model files.
Auto-Scaler
Logic that spins up 0-100 GPUs based on queue depth.
Registry
Container registry hosting the optimized inference image.
Implementation Details
Code Example
import runpod\n\ndef handler(job):\n job_input = job['input']\n prompt = job_input.get('prompt')\n # Model inference logic\n image = pipe(prompt).images[0]\n return { "image_url": upload_to_s3(image) }\n\nrunpod.serverless.start({"handler": handler})Agent Memory
Always enable 'FlashBoot' on RunPod. It caches your Docker layers on the host machine, reducing the image pull time from minutes to milliseconds.
Workflow
Process initiated
Analysis performed
Results delivered
Results & Impact
"RunPod allowed us to launch a viral AI app overnight. We went from 10 to 10,000 users without changing a single line of infrastructure code."
Elasticity
Perfect handling of 'Hacker News' traffic spikes.
Economics
Pay-per-second billing means zero waste.
Performance
Access to bleeding-edge H100s without contracts.
About the Author
Parmeet Singh Talwar
AI Context Engineer
Apex Neural
Parmeet engineers context-driven AI that combines LLMs with structured backend architecture and multi-platform integrations. He builds AI-powered systems with secure OAuth, fine-tunes open-source LLMs, and integrates image and video generation into production pipelines. Focused on clean design and system reliability.
Contributors

Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.