Scalable Infrastructure Automation for Multi-Tenant SaaS Platform
How we architected and automated cloud infrastructure for a multi-tenant SaaS platform serving 10K+ users across 500+ organizations, implementing automated scaling, deployment orchestration, comprehensive monitoring, and tenant isolation while reducing infrastructure costs by 40% through intelligent resource optimization.


Project Overview
Our multi-tenant SaaS platform providing HRM, CRM, and custom enterprise solutions required infrastructure that could scale dynamically while maintaining strict tenant isolation, cost efficiency, and operational reliability. The platform serves 10K+ users across 500+ organizations with varying usage patterns. Initial infrastructure was manually provisioned, couldn't handle traffic spikes (leading to 3-4 outages monthly), and infrastructure costs were 60% higher than industry benchmarks. We designed and implemented a comprehensive infrastructure automation solution using AWS services (EC2 Auto Scaling Groups, RDS with Multi-AZ, ElastiCache Redis Cluster, S3 with lifecycle policies, CloudFront CDN), Docker containerization, Terraform for Infrastructure as Code, GitLab CI/CD for deployment automation, and comprehensive monitoring using CloudWatch, Prometheus, and Grafana.
System Architecture
The infrastructure follows a three-tier architecture with high availability across multiple AWS Availability Zones. The presentation tier consists of CloudFront CDN for static assets and Application Load Balancer for dynamic content distribution. The application tier runs FastAPI/Django applications in Docker containers on EC2 instances managed by Auto Scaling Groups. The data tier includes RDS PostgreSQL Multi-AZ for transactional data, ElastiCache Redis Cluster for caching and sessions, and S3 for file storage. All tiers are deployed in a private VPC with public subnets for load balancers and private subnets for application and database servers. Security groups implement defense-in-depth with principle of least privilege.
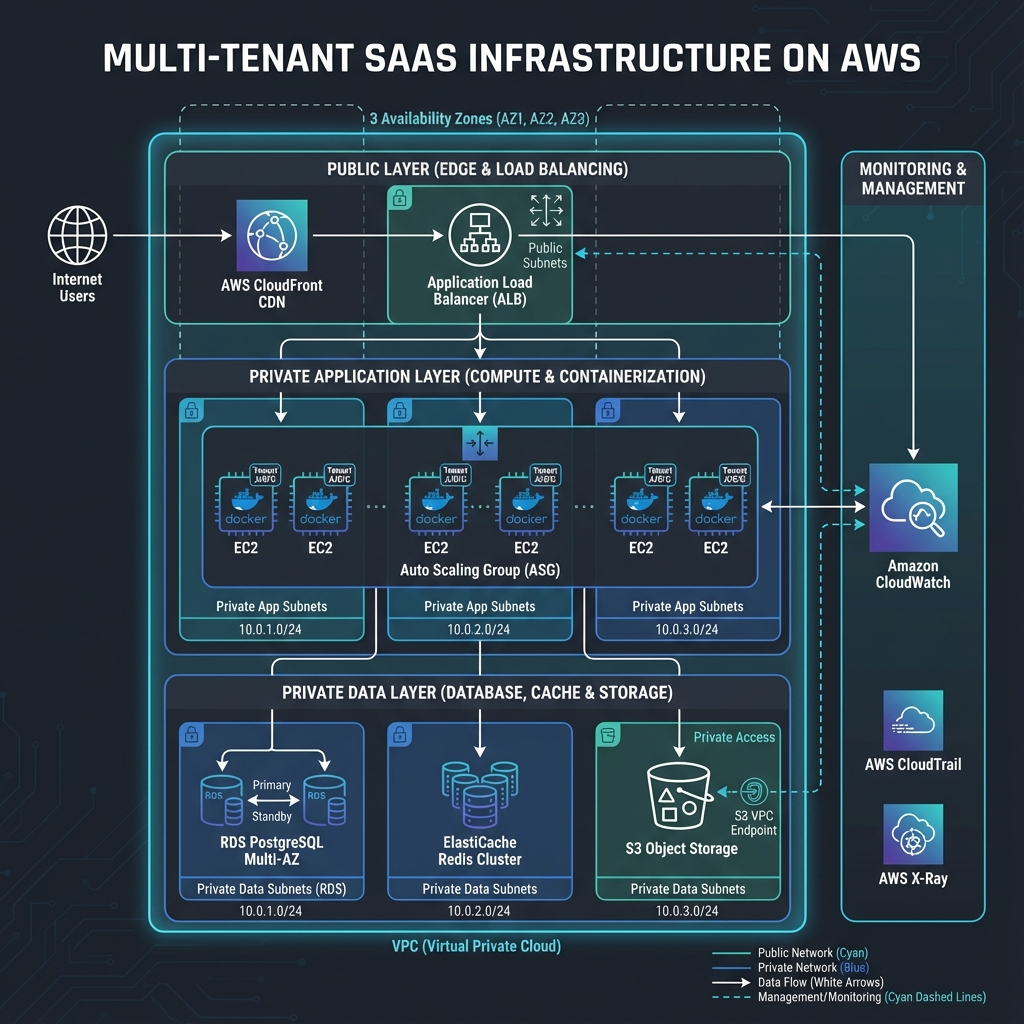
CloudFront CDN
Global content delivery network caching static assets with 95% cache hit rate reducing origin load
Application Load Balancer
Multi-AZ load balancing with SSL termination, health checks, and request routing based on path patterns
EC2 Auto Scaling Groups
Separate ASGs for web servers and workers with predictive scaling and automatic instance replacement
RDS PostgreSQL Multi-AZ
High-availability database with automatic failover, read replicas, and automated backup/recovery
ElastiCache Redis Cluster
Multi-node Redis cluster with automatic sharding, replication, and failover for caching and sessions
S3 with Lifecycle Policies
Object storage with intelligent tiering, versioning, and automated archival to Glacier for cost optimization
Implementation Details
Code Example
# Terraform - Auto Scaling Group Configuration
resource "aws_autoscaling_group" "web_servers" {
name = "saas-platform-web-asg"
vpc_zone_identifier = var.private_subnet_ids
min_size = 2
max_size = 20
desired_capacity = 4
health_check_type = "ELB"
launch_template {
id = aws_launch_template.web.id
version = "$Latest"
}
target_group_arns = [aws_lb_target_group.web.arn]
tag {
key = "Environment"
value = var.environment
propagate_at_launch = true
}
}
resource "aws_autoscaling_policy" "scale_out" {
name = "scale-out"
scaling_adjustment = 2
adjustment_type = "ChangeInCapacity"
cooldown = 300
autoscaling_group_name = aws_autoscaling_group.web_servers.name
}
resource "aws_cloudwatch_metric_alarm" "high_cpu" {
alarm_name = "high-cpu-utilization"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 2
metric_name = "CPUUtilization"
namespace = "AWS/EC2"
period = 60
statistic = "Average"
threshold = 70
alarm_actions = [aws_autoscaling_policy.scale_out.arn]
}Agent Memory
Use tenant-specific Redis key prefixes and separate connection pools to prevent cache poisoning and ensure complete tenant isolation. This also enables per-tenant cache eviction without affecting other tenants.
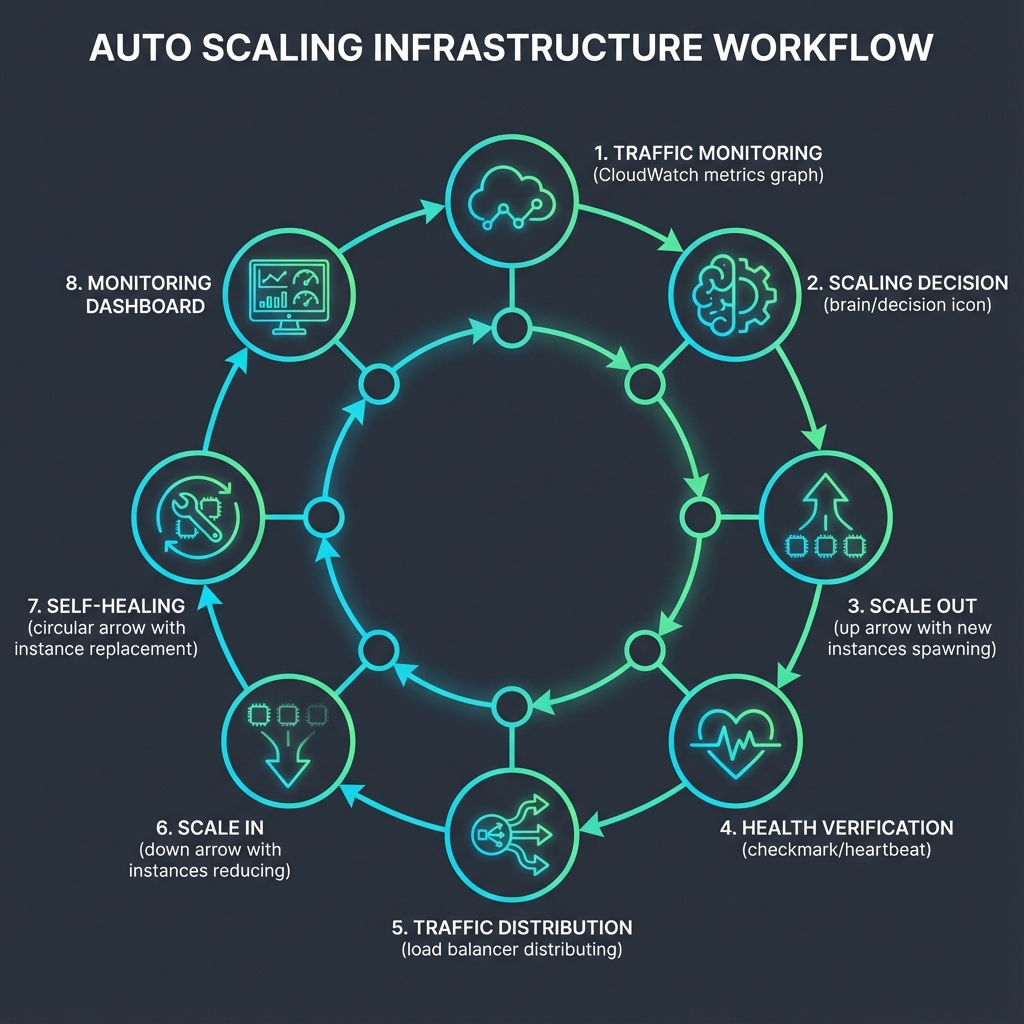
Workflow
Traffic Monitoring: CloudWatch monitors CPU, memory, request count, and custom application metrics in real-time.
Scaling Decision: Auto Scaling policies evaluate metrics against thresholds (CPU > 70%, memory > 80%, request latency > 500ms).
Scale Out: When thresholds exceeded for 2 consecutive periods, ASG launches new instances using latest AMI.
Health Verification: New instances must pass ELB health checks (3 consecutive successes) before receiving traffic.
Traffic Distribution: ALB gradually shifts traffic to new instances using slow start mode (5 minutes ramp-up).
Scale In: When load decreases below thresholds for 10 minutes, ASG terminates excess instances.
Self-Healing: Failed health checks trigger automatic instance termination and replacement.
Monitoring: Grafana dashboards show real-time scaling events, instance health, and cost metrics.
Results & Impact
"Our infrastructure now handles 10x traffic spikes without any manual intervention. We haven't had a single outage in 6 months, and our AWS bill is 40% lower than before despite supporting 3x more users."
Zero Outages
From 3-4 monthly outages to zero outages in 6 months
Cost Reduction
40% reduction in infrastructure costs through intelligent scaling and reserved instances
Scale Performance
Scales from 50 to 500+ concurrent users automatically in under 3 minutes
Database Performance
70% reduction in database load through intelligent caching strategies
Recovery Time
RTO of 15 minutes and RPO of 5 minutes for disaster recovery
About the Author
Ayush
AI Systems Architect
Apex Neural
Ayush is a Senior AI Systems Architect with 12+ years of experience building AI-first and SaaS platforms. He specializes in LLM-driven products, autonomous AI agents, and scalable enterprise systems using agentic design patterns like planning, reflection, tool use, and memory.
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.