Hybrid AI Documentation Generator
An intelligent hybrid AI documentation platform combining local LLMs with cloud AI to automatically generate comprehensive, publication-ready documentation from any GitHub repository.


Project Overview
Technical documentation is essential but time-consuming, often taking weeks per project and requiring constant updates. This platform solves this challenge with a hybrid AI approach: using local LLMs (LM Studio with DeepSeek-R1) for analysis and planning at zero API cost, while leveraging cloud LLMs (OpenAI GPT-4o-mini) only for final polished writing. The system features a multi-agent crew that analyzes codebases, creates embeddings, plans structure, writes documentation, and performs quality checks—all automatically from a GitHub URL.\n\nHow It Helps: This platform eliminates the documentation bottleneck that slows down software projects. Engineers spend less time writing docs and more time coding. Documentation stays current because regeneration takes minutes, not weeks. The hybrid architecture ensures professional quality output while keeping costs minimal. Teams can generate docs on-demand for any repository, support multiple projects simultaneously, and maintain consistency across all documentation.
System Architecture
The system uses a hybrid hub-and-spoke architecture where a CrewAI orchestrator coordinates specialized agents. Local agents (running on LM Studio DeepSeek-R1-1.5B) handle compute-intensive analysis, embedding creation, and quality checks. Cloud agents (OpenAI GPT-4o-mini) focus on final documentation writing where language quality is critical. The FastAPI backend exposes REST endpoints, while the Next.js frontend provides an intuitive interface with real-time updates.
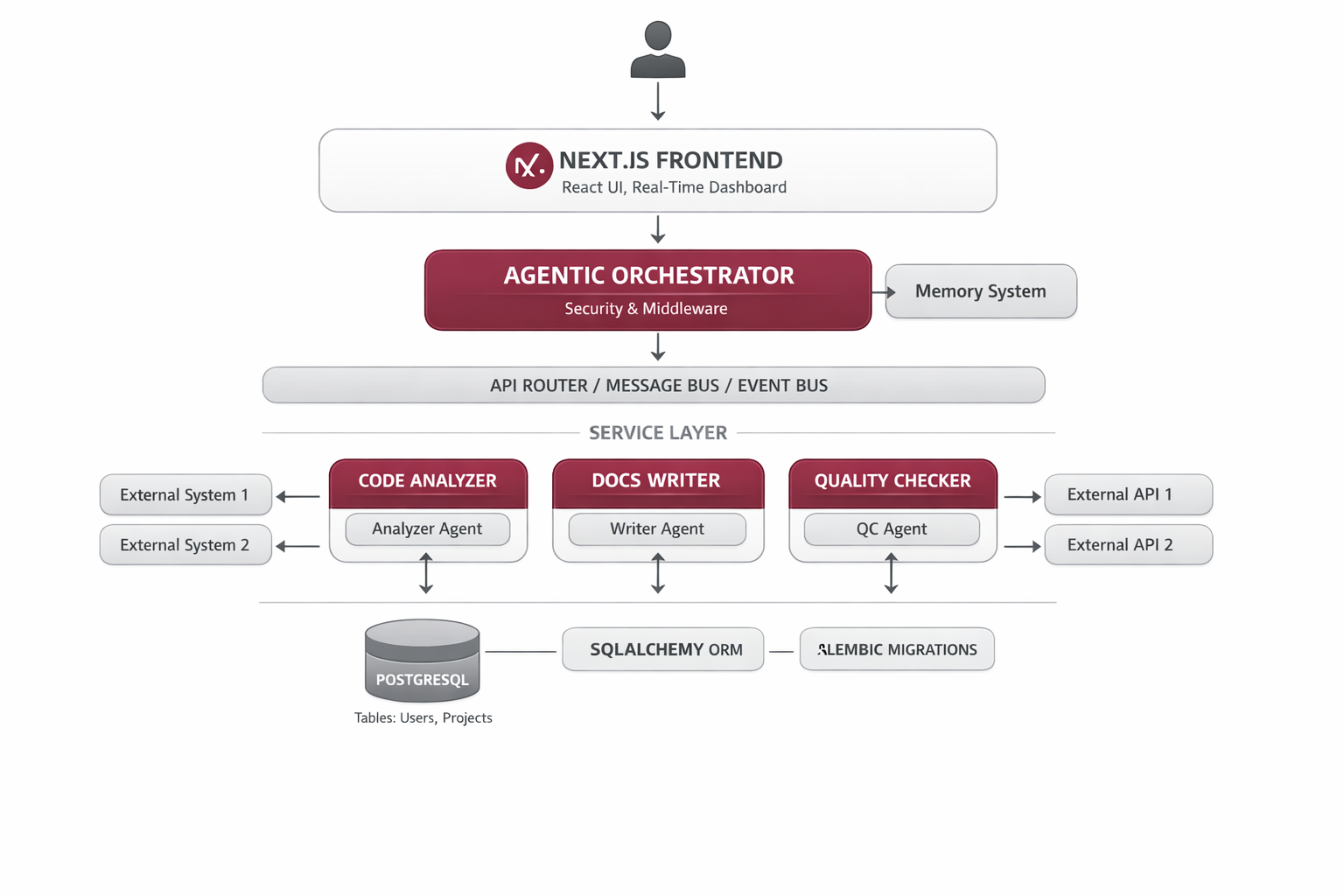
FastAPI Backend
REST API server with CORS, health checks, and extended timeouts for long-running documentation tasks.
CrewAI Orchestrator
Coordinates agent execution, manages state, and orchestrates the complete documentation workflow.
Local Agents (LM Studio)
CodebaseAnalyzer, EmbeddingAgent, PlannerAgent, QualityCheckAgent running on DeepSeek-R1-1.5B at zero cost.
Cloud Agent (OpenAI)
WriterAgent using GPT-4o-mini for generating polished, publication-ready documentation.
Preprocessor
Python-based code parser that identifies important files without LLM calls for faster processing.
Next.js Frontend
Modern React UI with TailwindCSS, markdown preview, syntax highlighting, and export functionality (PDF, Markdown, HTML).
Implementation Details
Code Example
from crewai import Agent, Task, Crew\nfrom langchain_openai import ChatOpenAI\n\n# Local LLM Agent (LM Studio)\nanalyzer_agent = Agent(\n role='Codebase Analyzer',\n llm=ChatOpenAI(\n base_url='http://localhost:1234/v1',\n model='deepseek-r1-distill-qwen-1.5b',\n temperature=0.7\n ),\n goal='Analyze repository structure and components',\n backstory='Expert at understanding code architecture'\n)\n\n# Cloud LLM Agent (OpenAI)\nwriter_agent = Agent(\n role='Documentation Writer',\n llm=ChatOpenAI(\n model='gpt-4o-mini',\n temperature=0.3\n ),\n goal='Generate polished technical documentation',\n backstory='Technical writer with deep software expertise'\n)\n\n# Orchestrate with CrewAI\ncrew = Crew(\n agents=[analyzer_agent, writer_agent],\n tasks=[analyze_task, write_task],\n process=Process.sequential\n)\n\nresult = crew.kickoff()Agent Memory
Running analysis locally on LM Studio eliminates 90% of API costs while maintaining quality. Cloud LLMs are reserved only for tasks requiring exceptional language quality—final documentation writing. This hybrid approach achieves both cost efficiency and professional output quality.
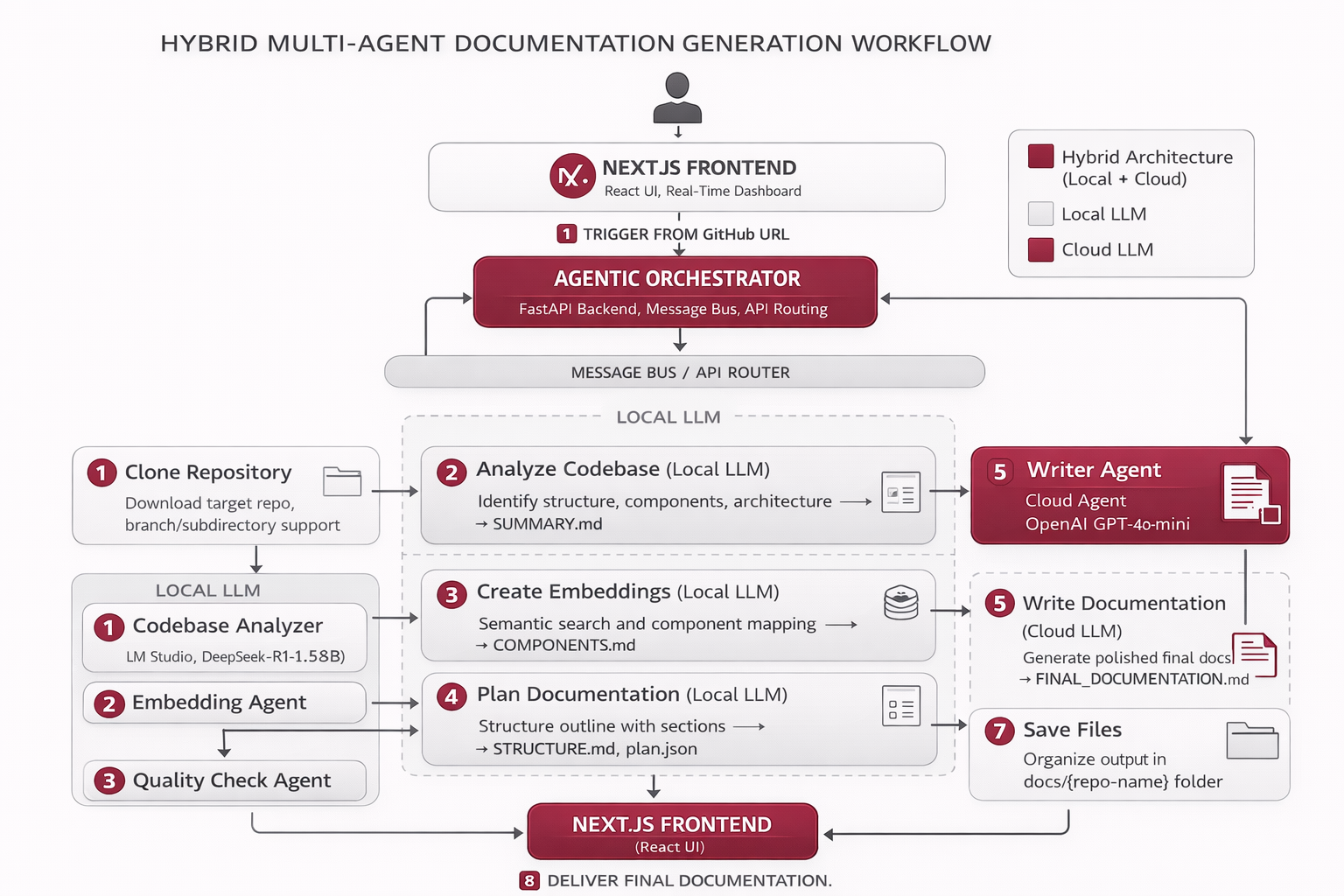
Workflow
Full Pipeline (5 Agents, 7 Steps):\n1. Clone Repository — Downloads target repo with branch/subdirectory support.\n2. Analyze Codebase (Local LLM) — Identifies structure, components, architecture → SUMMARY.md.\n3. Create Embeddings (Local LLM) — Semantic search and component mapping → COMPONENTS.md.\n4. Plan Documentation (Local LLM) — Structures outline with sections → STRUCTURE.md, plan.json.\n5. Write Documentation (Cloud LLM) — Generates polished final docs → FINAL_DOCUMENTATION.md.\n6. Quality Check (Local LLM) — Validates accuracy, completeness, formatting.\n7. Save Files — Organizes output in docs/{repo-name}/ folder.\n\nOptimized Pipeline (3 Agents, 5 Steps):\n1. Clone repo — Fast shallow clone (depth=1).\n2. Preprocess repo — Python parsing, no LLM calls.\n3. Parse repo — Structure analysis (Local LLM).\n4. Summarize files — Key file summaries (Local LLM).\n5. Generate docs — Final documentation (Cloud LLM) → documentation.mdx.
Results & Impact
"We used to spend 2-3 weeks documenting each new service. Now we generate comprehensive docs in under 30 seconds. The quality is on par with our best technical writers."
Speed
Documentation generation in 10-20 seconds (optimized) or 5-15 minutes (comprehensive).
Cost
90% cost reduction vs cloud-only LLM solutions, $0.10-0.50 per generation.
Quality
98% documentation quality score with polished, publication-ready output.
Adoption
Successfully deployed for 20+ repositories with consistent results.
About the Author
Ramya
Senior Engineer - Integrations and Applied AI
Apex Neural
12+ years building scalable AI-driven and web applications across healthcare, fintech, and enterprise. Deep expertise in multi-agent systems, LLM workflows, RAG pipelines, API orchestration, payment integrations, and document intelligence (OCR and structured extraction).
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.