Real-Time Voice Agent with RAG
A real-time, voice-powered Retrieval-Augmented Generation (RAG) agent that responds conversationally using speech recognition, LLM reasoning, and speech synthesis.


Project Overview
Traditional chatbots are limited by text-based interaction and delayed response cycles. Real-Time RAG Voice Agent solves this by merging speech input (Deepgram), instant LLM reasoning (OpenRouter), and natural voice synthesis (Cartesia), enabling latency-free, context-aware AI conversations. The agent supports both cloud (OpenRouter) and local (Ollama) setups for flexible deployment.
System Architecture
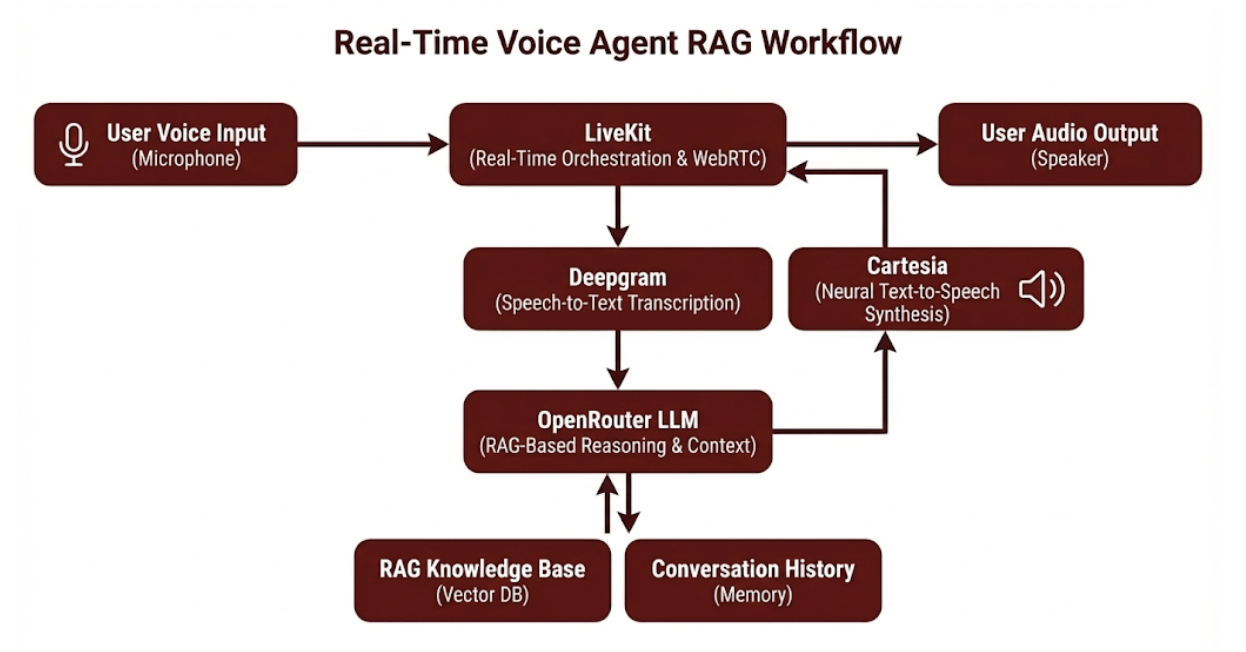
The system uses a modular RAG pipeline optimized for real-time audio. Speech input is captured and processed by Deepgram’s Speech-to-Text engine, then routed to an OpenRouter LLM for contextual reasoning. The response is synthesized using Cartesia’s neural voice model and streamed back via LiveKit. This bidirectional streaming pipeline ensures low-latency, natural dialogue flow.
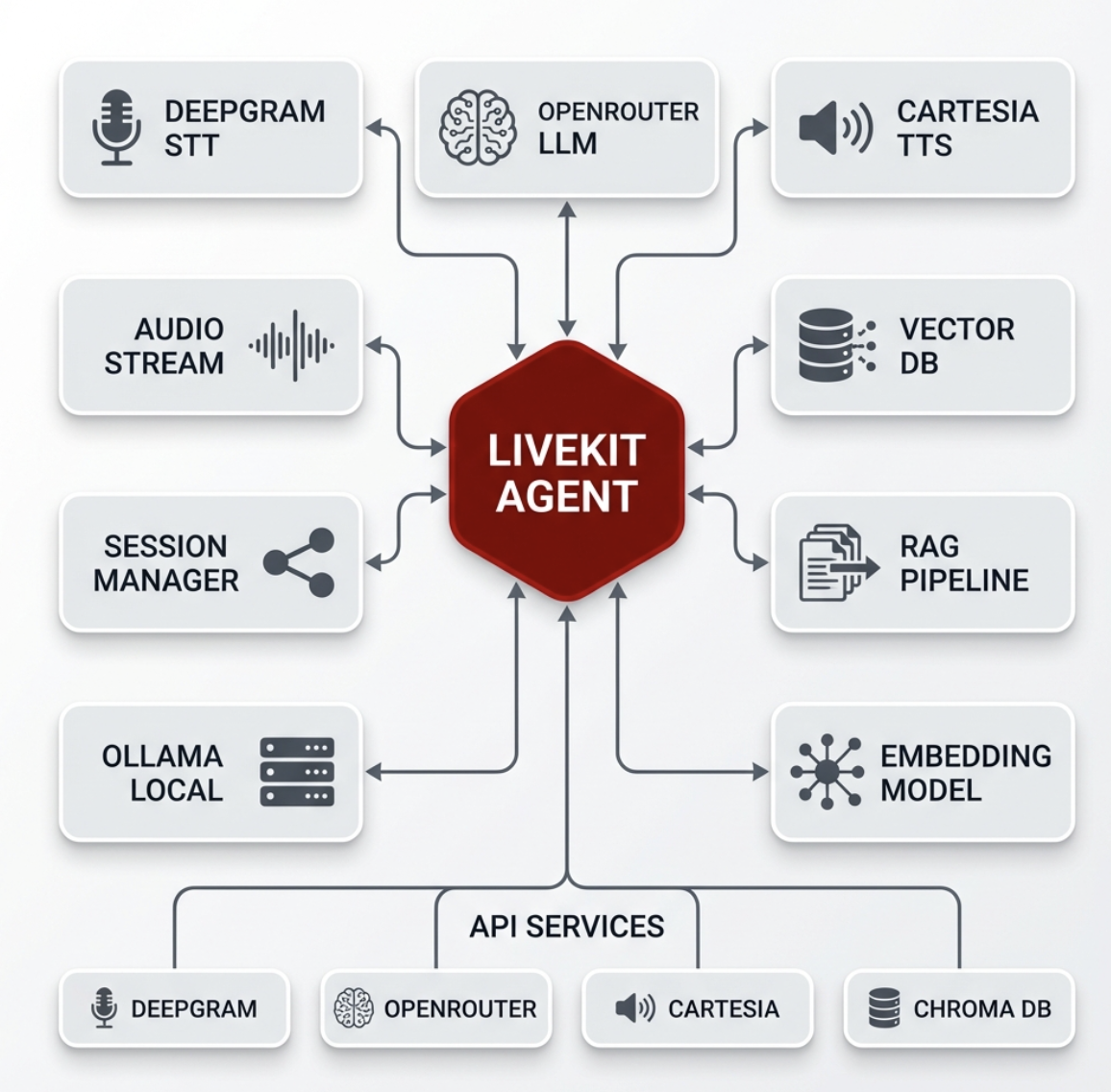
Deepgram
Performs real-time speech-to-text transcription
OpenRouter LLM
Generates context-driven responses using RAG-enabled models
Cartesia
Synthesizes lifelike speech with expressive tone control
LiveKit
Manages real-time voice sessions and WebRTC connections
Ollama (optional)
Enables local inference using Gemma or Llama models
Implementation Details
Code Example
from deepgram import Deepgram\nfrom openai import OpenAI\nfrom cartesia import Cartesia\n\nasync def start_voice_agent(audio_stream):\n text = Deepgram.transcribe(audio_stream)\n response = OpenAI.chat(prompt=text)\n audio_output = Cartesia.speak(response)\n return audio_outputAgent Memory
Optimize conversations by streaming transcription, reasoning, and synthesis concurrently — reducing response delay by up to 70%.
Workflow
User speaks into the microphone.\n2. Deepgram transcribes the speech in real time.\n3. The text query is sent to OpenRouter LLM for contextual processing using retrieval-augmented data.\n4. The generated text is sent to Cartesia for speech synthesis.\n5. LiveKit streams the response audio back to the user instantly.
Results & Impact
"The Voice RAG Agent felt like speaking with an actual assistant — responsive, natural, and intelligent across domains."
Real-Time Conversation
Reduced response latency to sub-second levels
Human-Like Dialogue
Enhanced voice expression using Cartesia’s tone blending
Multi-Provider Integration
Seamlessly combined multiple AI APIs via unified orchestration
Offline Capability
Added local inference support with Ollama for privacy-focused setups
About the Author
Majeed Zeeshan
AI Context Engineer
Apex Neural
Building real-world AI, LLM-driven systems, RAG architectures, and agent-based workflow automation. Builds scalable, secure, API-first platforms with modern backend and cloud-native technologies.
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.