LinkedIn Job Scraper: Scalable Data Harvesting with Apify
A production-ready guide on building resilient LinkedIn job scrapers using Apify Actors and Python, designed to bypass auth-walls and rate limits.


Project Overview
Scraping LinkedIn is notoriously difficult due to strict anti-bot measures. This case study details how we utilized Apify's infrastructure to deploy a robust scraper that rotates residential proxies and manages browser fingerprints. The system extracts job titles, descriptions, and salary ranges, cleaning the data into a standardized JSON format for analysis.
System Architecture
The architecture leverages Apify Actors to handle the heavy lifting of browser orchestration. A central 'Manager' script queues job URLs, while worker actors scrape data in parallel using stealth-mode Playwright. Data is pushed to an Apify Dataset and eventually synced to a PostgreSQL warehouse.
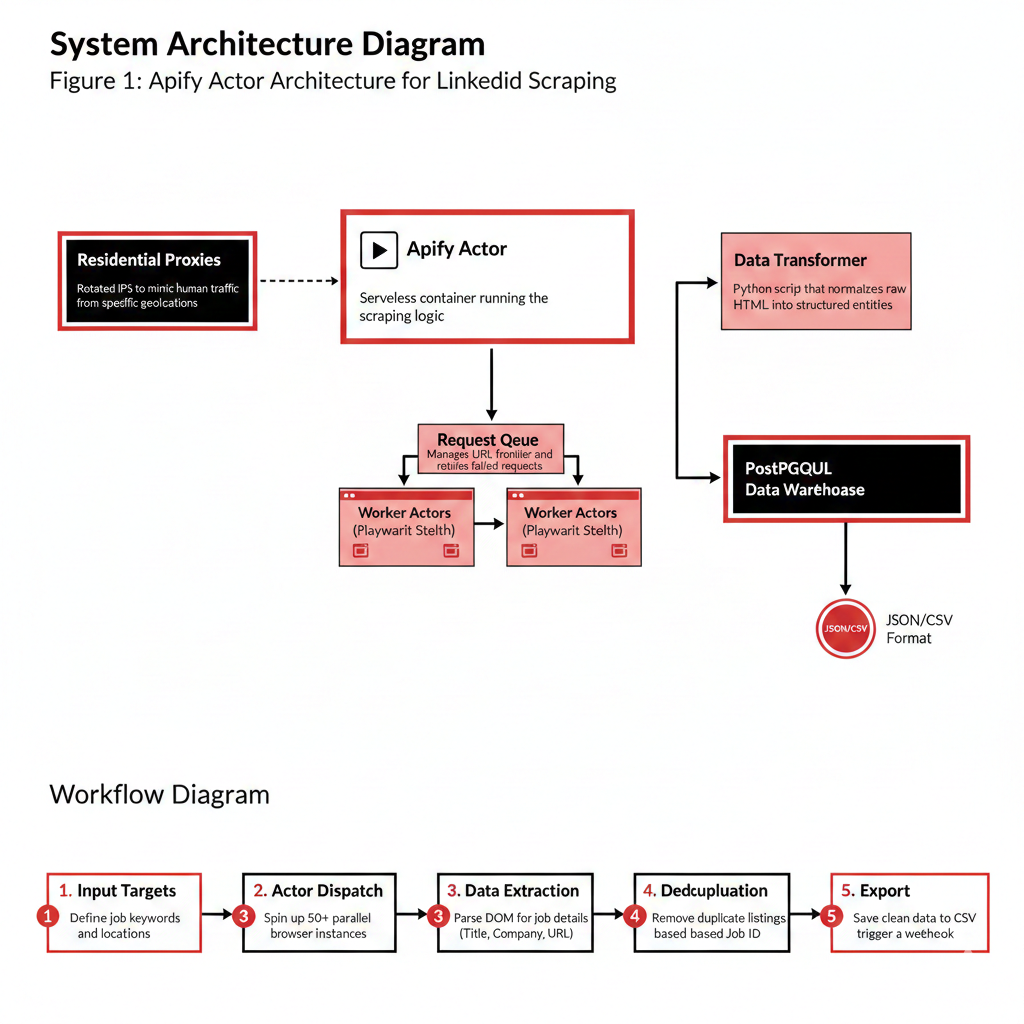
Apify Actor
Serverless container running the scraping logic.
Residential Proxies
Rotated IPs to mimic human traffic from specific geolocations.
Request Queue
Manages URL frontier and retries failed requests.
Data Transformer
Python script that normalizes raw HTML into structured entities.
Implementation Details
Code Example
from apify_client import ApifyClient\n\ndef scrape_linkedin_jobs(keywords):\n client = ApifyClient('MY_TOKEN')\n run_input = {\n "keywords": keywords,\n "locationId": "103644278", # United States\n "limit": 100\n }\n # Start the actor and wait for finish\n run = client.actor("trudax/linkedin-job-scraper").call(run_input=run_input)\n # Fetch results\n return list(client.dataset(run["defaultDatasetId"]).iterate_items())Agent Memory
Don't just rotate IPs; rotate Session IDs and Cookies. Apify's SessionPool manages this automatically, retiring sessions that get flagged or blocked to keep the scraper healthy.
Workflow
Input Targets: Define job keywords and locations.\n2. Actor Dispatch: Spin up 50+ parallel browser instances.\n3. Data Extraction: Parse DOM for job details (Title, Company, URL).\n4. Deduplication: Remove duplicate listings based on Job ID.\n5. Export: Save clean data to CSV or trigger a webhook.

Results & Impact
"Using Apify allowed us to scale from 100 jobs a day to 100,000 without worrying about server maintenance or IP bans."
Scale
Unlimited horizontal scaling via serverless actors.
Reliability
Automatic retries handle transient network failures.
Freshness
Real-time market insights with hourly runs.
About the Author
Parmeet Singh Talwar
AI Context Engineer
Apex Neural
Parmeet engineers context-driven AI that combines LLMs with structured backend architecture and multi-platform integrations. He builds AI-powered systems with secure OAuth, fine-tunes open-source LLMs, and integrates image and video generation into production pipelines. Focused on clean design and system reliability.
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.