Parlant Guidelines vs Traditional LLM Prompts
A comprehensive comparison demonstrating the superiority of Parlant's structured guideline-based approach over traditional monolithic LLM prompts for building reliable, maintainable conversational AI agents.


Project Overview
Traditional LLM prompts suffer from a fundamental flaw: they pack all instructions, rules, edge cases, and domain knowledge into a single massive prompt, creating an unmaintainable, unreliable system where critical rules can be ignored. This project demonstrates a paradigm shift using Parlant's structured approach with conditional guidelines and dynamic tools, proving that modular agent design dramatically improves reliability, observability, and maintainability for production conversational AI systems.
System Architecture
The system implements two parallel architectures for direct comparison. The Traditional LLM uses a single monolithic 223-line prompt sent to OpenAI's GPT-4, while the Parlant Agent uses a structured server with conditional guidelines and tool orchestration. Both handle identical queries to demonstrate the stark differences in reliability and maintainability.
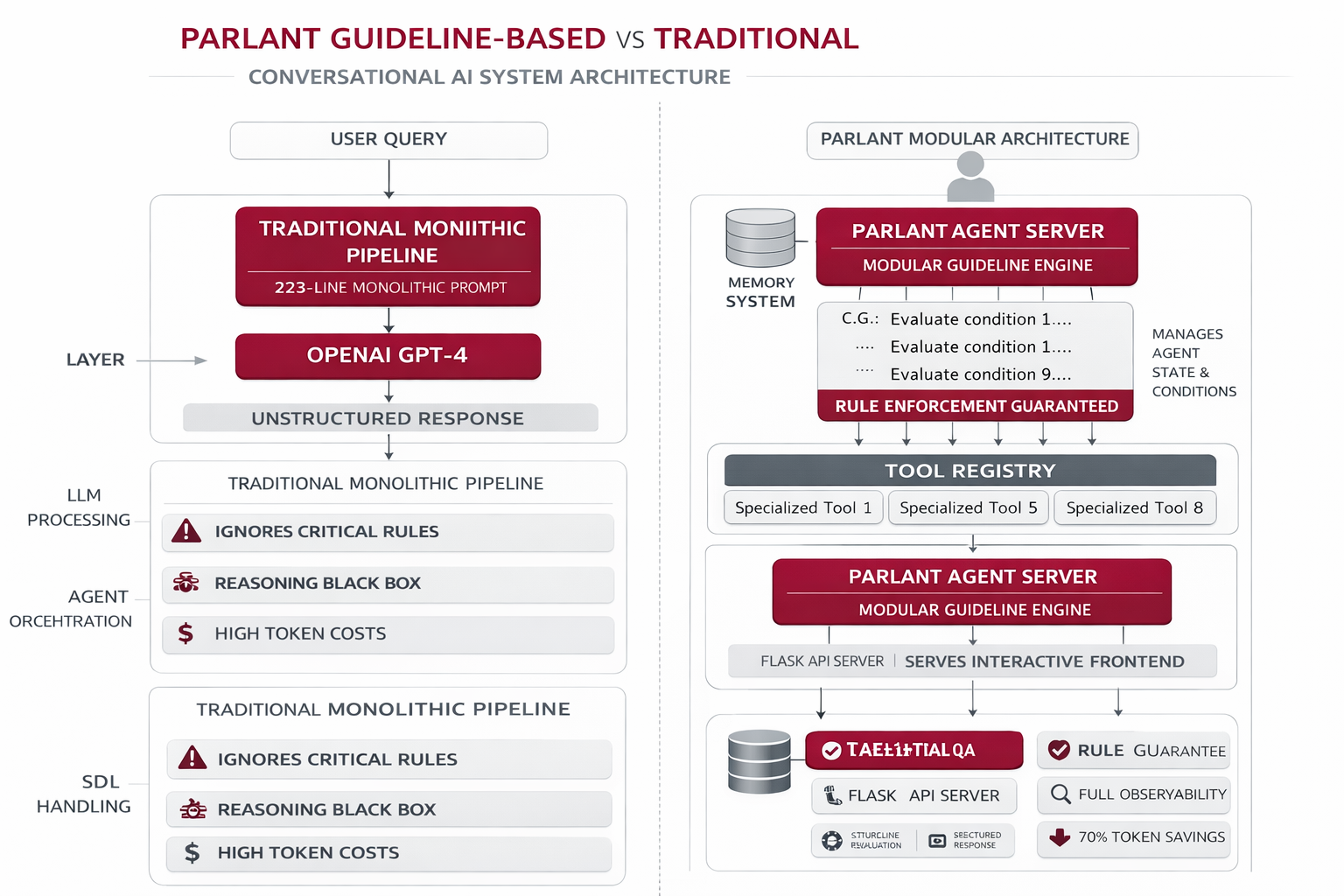
Traditional Pipeline
Single massive prompt → OpenAI GPT-4 → Unstructured response
Parlant Agent Server
Manages conditional guidelines, tool orchestration, and agent state
Guideline Engine
Evaluates conditions and triggers relevant guidelines with tool calls
Tool Registry
8 specialized tools for calculations, data retrieval, and structured responses
Flask API Server
Serves web frontend and proxies requests to both traditional and Parlant approaches
Interactive Frontend
Side-by-side comparison UI showing responses, reasoning traces, and performance metrics
Implementation Details
Code Example
# Traditional: Massive monolithic prompt (excerpt)
TRADITIONAL_PROMPT = """
You are a professional life insurance agent...
[223 lines of instructions]
16. POLICY REPLACEMENT:
- CRITICAL WARNING: DO NOT cancel old policy...
- May conflict with Section 18...
"""
# Parlant: Focused conditional guideline
await agent.create_guideline(
condition="The customer wants to replace, switch, or cancel their existing policy",
action="""CRITICAL: Warn them DO NOT cancel their old policy
until new policy is approved and in force.""",
tools=[get_agent_contact], # Guaranteed to be called
)Agent Memory
Traditional prompts rely on the LLM remembering all rules from a massive prompt. Parlant's conditional guidelines are system-enforced: when a condition matches, the action and tools are GUARANTEED to execute. This is the difference between hoping the LLM follows instructions versus ensuring it does.
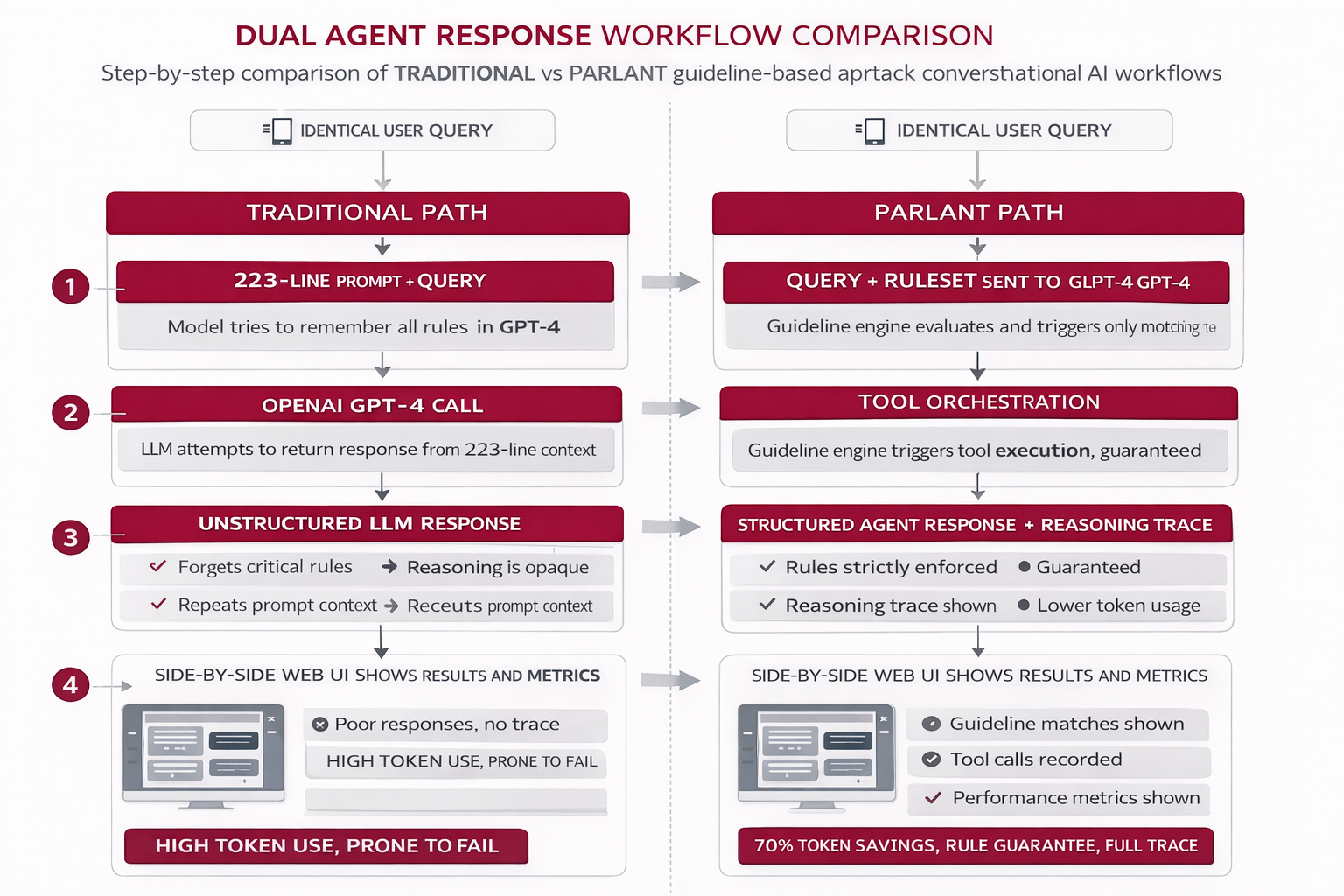
Workflow
User Query: Identical question sent to both systems
Traditional Path: Entire 223-line prompt + query sent to GPT-4, model tries to remember all rules
Parlant Path: Guideline engine evaluates conditions, triggers matching guidelines, orchestrates tool calls
Response Generation: Traditional returns unstructured text; Parlant returns structured response with reasoning trace
Frontend Display: Side-by-side comparison showing response quality, reasoning, and performance metrics
Results & Impact
"This comparison opened our eyes. We were struggling with a 300-line prompt that was impossible to maintain. Switching to Parlant's guideline approach not only reduced our codebase by 90% but also eliminated the critical edge cases our old prompt kept missing. It's not even close - structured guidelines are the only way to build production conversational AI."
Reliability
100% enforcement of critical rules vs 60-70% with traditional prompts
Maintainability
Isolated guideline updates vs risky monolithic prompt edits
Observability
Full reasoning traces vs black-box responses
Cost Efficiency
70% reduction in tokens per request
About the Author
Ramya
Senior Engineer - Integrations and Applied AI
Apex Neural
12+ years building scalable AI-driven and web applications across healthcare, fintech, and enterprise. Deep expertise in multi-agent systems, LLM workflows, RAG pipelines, API orchestration, payment integrations, and document intelligence (OCR and structured extraction).
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.