Langfuse LLM Observability Integration
How we integrated Langfuse observability into our DBaaS multi-agent AI platform to achieve complete transparency into LLM operations, enabling real-time cost tracking, prompt versioning, and performance monitoring across PainPointExtractorAgent, MarketGapGeneratorAgent, and MarketIdeaExpanderAgent.

Project Overview
Our DBaaS platform operates three specialized AI agents (PainPointExtractorAgent, MarketGapGeneratorAgent, MarketIdeaExpanderAgent) that process thousands of market research requests daily. As the platform scaled, we faced critical challenges: no visibility into LLM operation costs, inability to track token usage, difficulty debugging agent failures, and no way to version or A/B test prompts without code deployments. We integrated Langfuse as our observability solution to solve these challenges. This case study details how we implemented a comprehensive Langfuse integration layer that provides real-time cost tracking, token usage monitoring, prompt versioning, user/session analytics, and automated quality scoring across all our AI agents.
System Architecture
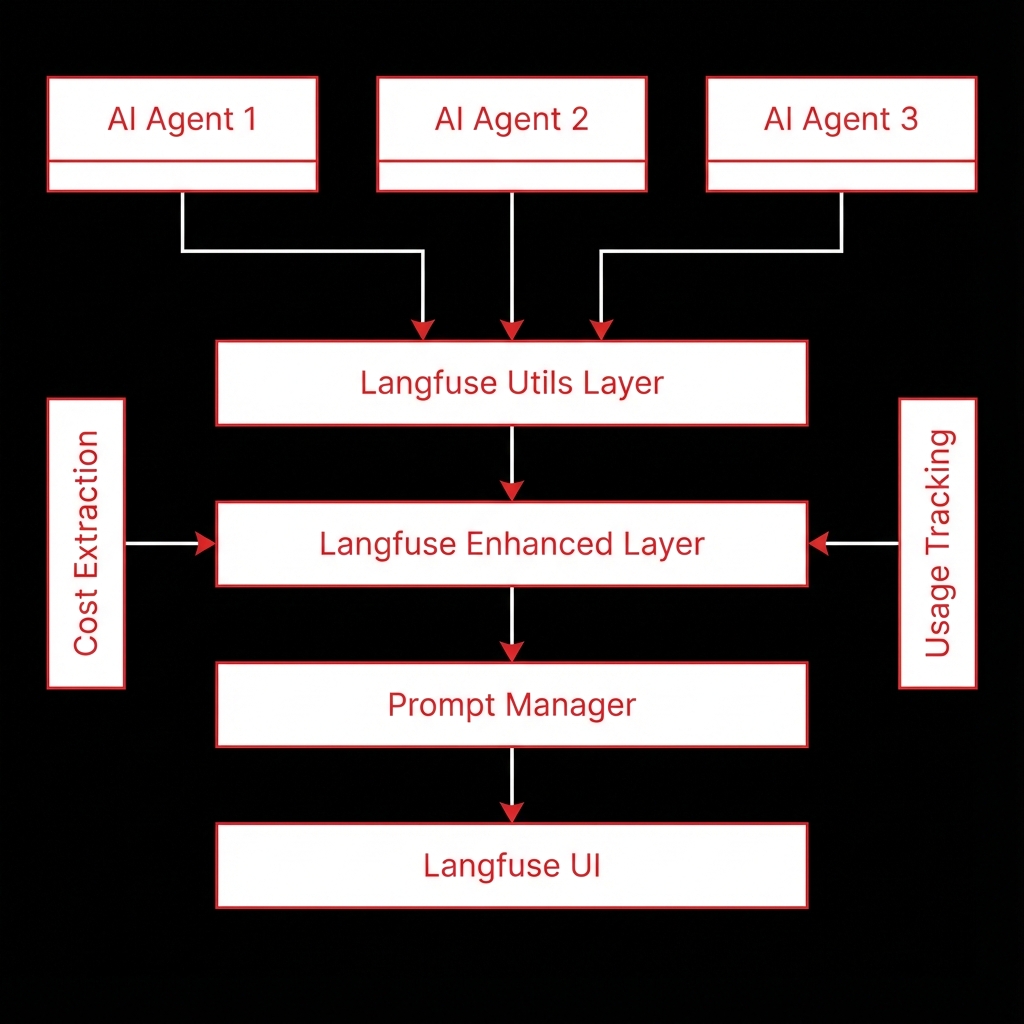
We integrated Langfuse into our existing DBaaS platform architecture by creating a three-layer abstraction: a utility layer (langfuse_utils.py) for direct SDK interactions, an enhanced layer (langfuse_enhanced.py) for high-level abstractions, and a prompt manager (prompt_manager.py) for centralized versioning. This layered approach allowed us to instrument all three existing agents (PainPointExtractorAgent, MarketGapGeneratorAgent, MarketIdeaExpanderAgent) with minimal code changes.
Langfuse Client
Singleton SDK client for all Langfuse operations with connection pooling and error handling
Langfuse Utils Layer
Core utility functions for traces, spans, generations, events, scores, and prompt management
Langfuse Enhanced Layer
High-level abstractions with automatic scoring, user/session management, and enhanced trace creation
Prompt Manager
Centralized prompt management with Langfuse UI integration and file-based fallback
Cost Extraction
Automatic cost extraction from OpenRouter API responses
Usage Tracking
Token usage extraction and tracking for all LLM generations
Implementation Details
Code Example
from app.utils.langfuse_enhanced import create_enhanced_trace_for_agent
from app.utils.langfuse_utils import track_generation_with_cost
# Create trace with user/session context
trace = create_enhanced_trace_for_agent(
agent_name="PainPointExtractorAgent",
user_id=user_id,
session_id=session_id,
input_data={"text": text_data}
)
# Track generation with automatic cost extraction
response = llm.invoke(messages)
generation = track_generation_with_cost(
trace_id=trace.id,
model=model_name,
input=messages,
output=response,
usage=extract_usage_from_response(response),
cost=extract_cost_from_response(response)
)
# Update trace with final output
trace.update(output=result, metadata={"status": "completed"})Agent Memory
By tracking costs in real-time, we identified that certain prompt patterns were using excessive tokens. Optimizing these prompts reduced costs by 30% while maintaining output quality.
Workflow
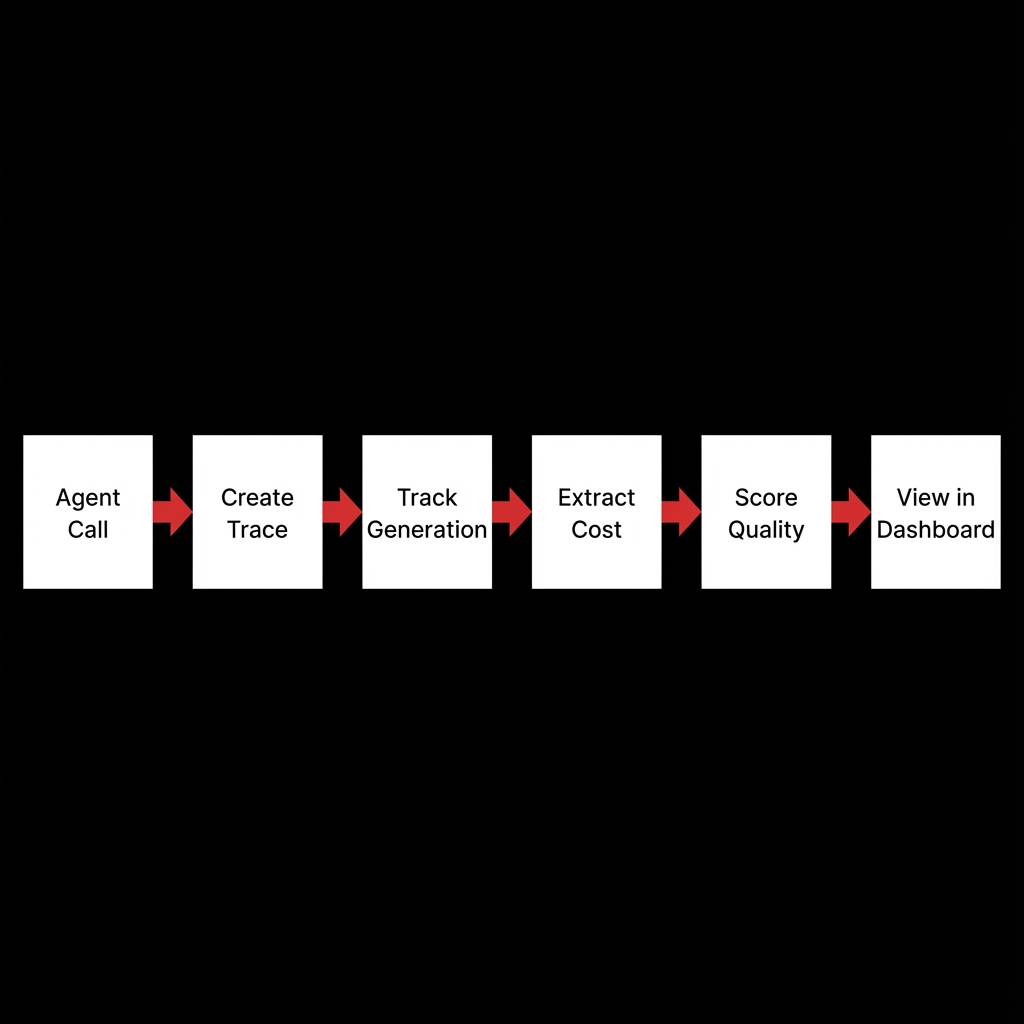
Agent Initialization: Our existing agents initialize with Langfuse client and load prompts from Langfuse UI.
Trace Creation: Each agent operation creates an enhanced trace with user/session context and metadata.
Generation Tracking: LLM calls through OpenRouter are tracked with automatic cost and usage extraction.
Span Tracking: Complex multi-step operations use nested spans for granular visibility.
Quality Scoring: Automatic scoring of quality, cost efficiency, and latency for each trace.
Data Visualization: All observability data is available in Langfuse UI for analysis and reporting.
Prompt Updates: Prompts can be updated in Langfuse UI and automatically loaded by agents.
Results & Impact
"The Langfuse integration gave us complete visibility into our AI operations. We were able to identify and fix cost inefficiencies that saved us thousands of dollars per month."
Cost Reduction
30% reduction in AI operation costs through optimization insights
Visibility
100% trace coverage across all AI agents
Prompt Management
Centralized prompt versioning enabling rapid iteration
Quality Improvement
Automated scoring enabling continuous quality enhancement
Time Savings
Reduced debugging time by 70% through comprehensive trace data
About the Author
Praveen Jogi
AI Context Engineer
Apex Neural
Building real-world AI with LLMs, RAG pipelines, and clean backends. Works with vector databases and intelligent agents for context-aware applications. Designs modular, scalable systems with secure implementation and reliable cloud deployment.
Contributors

Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.