IP-Adapter: The Image Prompt Revolution
Understanding the 'Image Prompt Adapter', a lightweight module that allows diffusion models to 'see' reference images. The secret weapon for style cloning and composition.


Project Overview
Text prompts are often insufficient to describe complex visual styles or specific objects. IP-Adapter (Image Prompt Adapter) solves this by decoupling the cross-attention mechanism. It allows you to feed an image (e.g., a specific wooden chair, or a specific Van Gogh painting) into the model as a prompt. The model then generates new content that mimics the *content* or *style* of that reference with uncanny accuracy.
System Architecture
Unlike LoRAs which require fine-tuning, IP-Adapter is a plug-and-play module. It uses a separate image encoder (CLIP Vision) to extract feature embeddings from the reference image. These embeddings are then projected into the UNet's cross-attention layers, effectively 'hijacking' the text prompt pathway to pay attention to visual features instead.
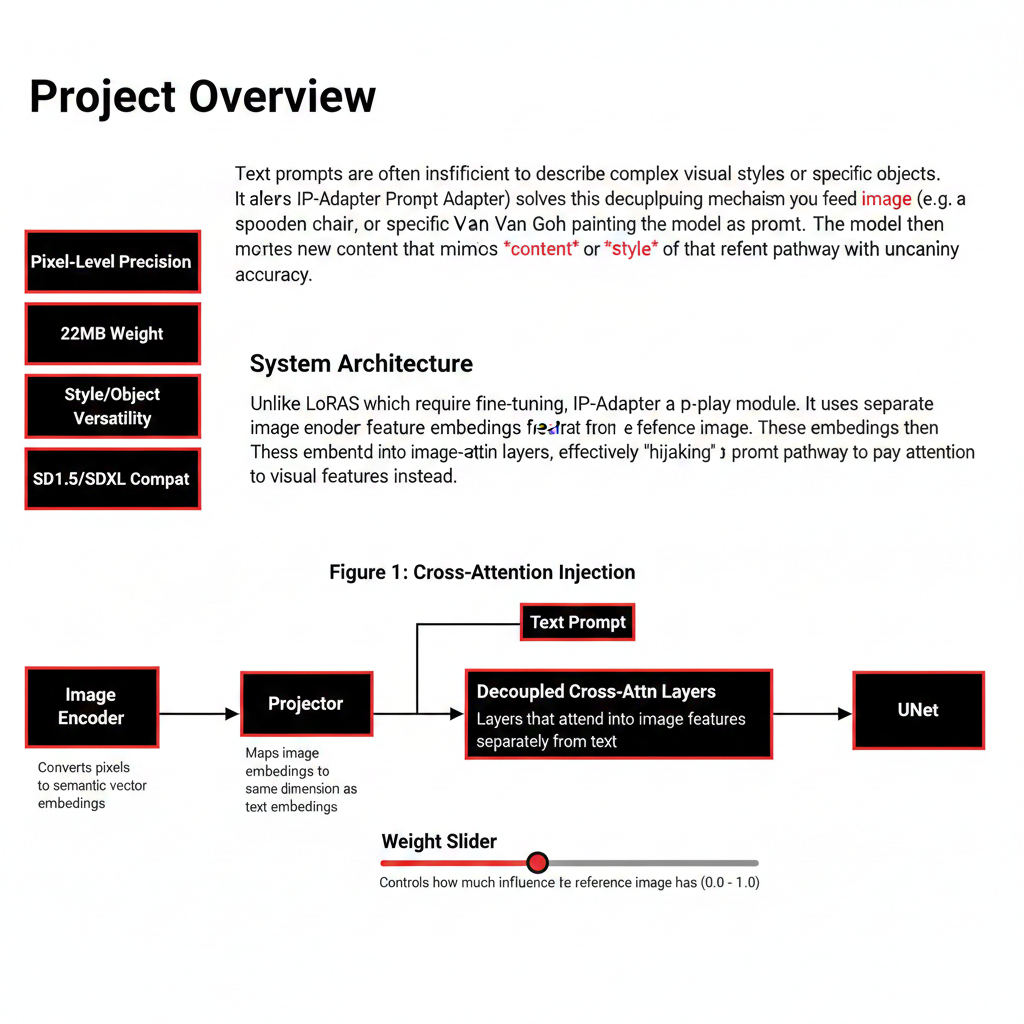
Image Encoder
Converts pixels to semantic vector embeddings.
Projector
Maps image embeddings to the same dimension as text embeddings.
Decoupled Cross-Attn
Layers that attend to image features separately from text.
Weight Slider
Controls how much influence the reference image has (0.0 - 1.0).
Implementation Details
Code Example
# Using IP-Adapter for Style Transfer\nstyle_image = load_image("starry_night.jpg")\ncontent_image = load_image("my_dog.jpg")\n\n# IP-Adapter guides style, ControlNet guides structure\ngenerated = pipe(\n prompt="a dog",\n ip_adapter_image=style_image, # Style ref\n controlnet_image=content_image # Structure ref\n).images[0]Agent Memory
You can chain multiple IP-Adapters! Use one adapter for 'Style' (weight 0.8) and another for 'Object Structure' (weight 0.5) to compose complex scenes without a single word of text.
Workflow
Process initiated
Analysis performed
Results delivered
Results & Impact
"IP-Adapter kills the need for 'prompt engineering'. I just show the model what I want, and it understands instantly."
Zero-Shot
Works on any style without training.
Coherence
Maintains object integrity better than text.
UX
Enables 'visual prompting' interfaces.
About the Author
Parmeet Singh Talwar
AI Context Engineer
Apex Neural
Parmeet engineers context-driven AI that combines LLMs with structured backend architecture and multi-platform integrations. He builds AI-powered systems with secure OAuth, fine-tunes open-source LLMs, and integrates image and video generation into production pipelines. Focused on clean design and system reliability.
Ready to Build Your AI Solution?
Get a free consultation and see how we can help transform your business.